1、VeNICE: A very deep neural network approach to no-reference image assessment.
1.1框架:总共包括5个group,group1:conv,conv,relu,maxpool;group2:conv,conv,relu,maxpool;group3:conv,conv,conv,relu,maxpool;group4:conv,conv,conv,relu,maxpool;group5:conv,conv,conv,relu,maxpool;卷积层的参数直接fine-tuneVGG16的参数。全连接层:49-512-4096-1。

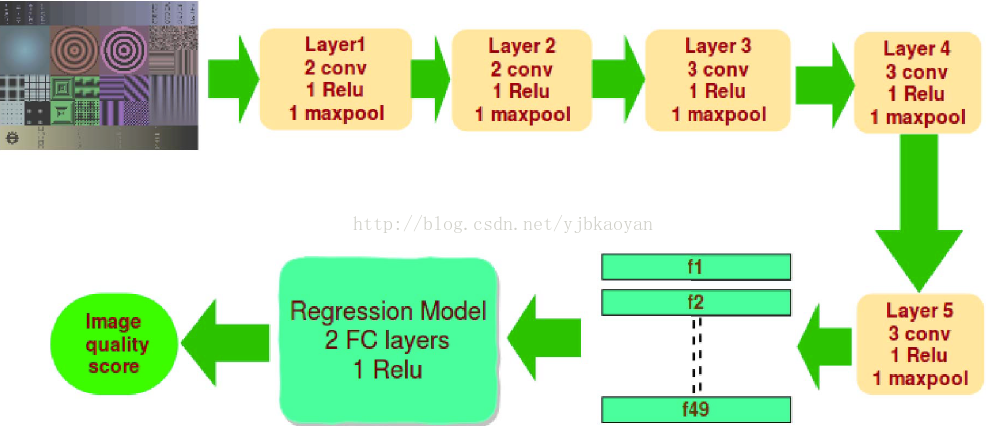
1.2 参数设置:input:224*224;batch size:7;epochs:200;learning rate:0.0001
2、2016ICASSP:Blind image quality assessment formultiply distorted images via convolutional networks. 同济大学
2.1相比于2014年的CVPR(Le Kang),此篇论文增加了feature map的数量,增加了全连接的数量。
2.2 Conv + max pool,average pool,dense 2048, dense 2048, output.
2.3 卷积层后面接Relu,对输入进行normalization处理。注:与MSCN不同,类似。
2.4 实验部分:75% train set, 25% fortesting. 取三次的平均结果。SROCC:0.9703
3. 2016ISCID:Blind image quality assessment via convolutional neural network.
----CNN提取features, SVR用来回归分数。
----和Kang Le的框架一样。只不过在pooling的时候,选择了四种pooling strategies. Max,min, mean, variance。
----conv + pool + dense 800 + dense 800 + output
搞不懂为什么定义成一个分类的问题???
4. 2017IEEESignal Processing Magazine: Deep convolutional neural models for picturequality prediction. Jongyoo Kim, 很厉害!!!
----第一种方法:用AlexNet(4096维),ResNet(2048维)提取features,用SVR做回归训练。其中,每一张图像随机提取25个图像块,将获得的25个特征向量进行平均处理。作为SVR的input。
----第二种方法:使用pre-train的AlexNet和ResNet完成end to end的训练。每张图像提取100 patches,损失函数:L1 Norm,dropout rate: 0.5,Learning rate: 0.001,8 and 6 epochs on AlexNet andResNet 50。Batch size: 50。测试时:随机从图像中截取25个图像块,预测得到的25个分数进行平均,为测试图像的分数。
----第三种方法:training from scratch,architecture: Conv-48,Conv-48, withstride 2,Conv-64,Conv-64,with stride 2,Conv-64,Conv-64,Conv-128,Conv-128,FC-128,FC-128,FC-1。使用3*3的filters。最后一层的时候,直接对每一个feature map进行average操作,变成了128维,后面就直接跟着全连接层了。(这样大大的减少了参数),损失函数:L2 Norm,每一张图像分成112*112 patches。有一个数据的扩增操作:水平翻转。每一个minbatch中,包含来自5张图像的patch。训练80 epoach。
5、2017ICCV:RankIQA: Learning from rankings forno-reference image quality assessment, XiaLei Liu, 有代码
采用2005CVPR的相似结构,【Gw(X1)为网络输出的features,该网络结构学习的目的是两张相似的图片,其获得的结果也是相似的】,该论文结构与Kede Ma 2017TIP的网络结构是一样的,只不过Kede Ma的网络结构是全连接的,而该论文使用一些比较出名的网络进行试验,如AlexNet,VGG16。输入是一张图像,输出是图像的质量。在训练时,输入是两张图像,分别得到对应的分数,将分数的差异嵌入loss层,再进行反向传播。
训练时,每次从图像中随机提取224*224或者227*227大小的图像块。和AlexNet、VGG16有关。在训练Siamese network时,初始的learning rate 是1e-4;fine-tuning是初始的learning rate是1e-6,每隔10k步,rate变成原来的0.1倍。训练50k次。
测试时,随机在图像中提取30个图像块,得到30个分数之后,进行均值操作。
6. 2017TIP.Waterloo Exploration Database: New Challenges for Image Quality AssessmentModels.
---- D测试:检验IQA模型是否能够较好地分开原始图像和失真图像。
---- L测试:检验同一种失真类型下,不同程度失真图像的consistent ranking。
---- P 测试:检验算法偏好的一致性,是否能将质量差异明显的图像分开。
6.1 如何生成DIPs.
使用三种全参考图像质量评价方法,包括MS-SSIM,VIF,GMSD。在生成DIPs之前,将计算得到的客观分数,映射到同一个尺度下,比如与LIVE数据库的尺度一样。
7、2017TIP,Kede Ma, End to end blind imagequality assessment using deep neural networks.
7.1、Network:
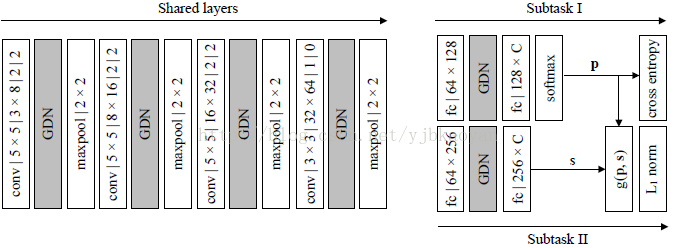
训练时,是多阶段的。Subtask I, 训练一个分类网络,输出是一个向量,表示图像属于哪种失真的概率,损失函数为交叉熵。Subtask II, fine tunesubtask I的参数。并且将subtask I的输出与预测层的向量进行点乘. 测试时,给定一张图像,随机提取256*256*3的图像块,图像的失真类型由图像块的失真类型投票所得。图像的分数为所有图像块分数的均值。
转载自原文链接, 如需删除请联系管理员。
原文链接:近期deep learning做图像质量评价(image quality assessment)的论文3,转载请注明来源!