强化学习是一门决策学科,理解最佳的方式来制定决策。在工程控制当中有一门学习叫最优控制,与强化学习使用的方法有很大的类似之处,这种基于强化学习的方法不需要建模,也不需要设计控制器,只需要构建一个强化学习算法。在神经科学,或者认知神经科学领域,强化学习主要是在模仿人类大脑的工作原理,人类大脑的控制在很大程度上取决于多巴胺的分泌。在心理学领域,我们理解的是认为如何对外部环境变化做出反应,为什么会做出这种反应。在数学领域研究的是如何数学推导得出最优控制的解,这个也被称作为运筹学。在博弈论里面我们研究的也是我们如何做出决策,才能得到最大的效益。强化学习方法可以分为基于值函数的强化学习算法、基于策略函数的强化学习算法、以及AC的方法。
强化学习与监督学习的第一个不同之处是:在强化学习里面,没有人会告诉你应该采取什么样的动作,外部环境只会告诉你你采取的动作是好的还是坏的,而不是直接告诉你什么是应该采取的动作。这是一个类似小孩的试错学习。
强化学习与监督学习的第二个不同之处是:我们得到的奖励并不是立刻得到的,我们有可能是在很多步之后得到这个奖励。你可能在很多步之后才会知道这个动作是好的动作还是坏的动作。也有可能你采取了一个动作之后得到一个小的奖励,但是在之后的序列决策过程中,你将会得到毁灭性的打击。这是reinforcement learning的一大特点。
强化学习与监督学习的第三个不同之处是:在监督学习中,假设数据是独立同分布的,预测数据和训练数据的分布是一致的。但在强化学习中,这个基本的假设是不成立的,因为在智能体会通过动作改变环境,从环境中获取的数据也会不断发生改变。
在强化学习中智能体所做的是序贯决策问题,序贯决策问题就是需要连续不断地做出决策,才能实现最终目标的问题。这也就是说我们的数据是不满足独立同分布的。我们需要应对的是一个动态系统,每一个动作都会影响下一个状态。所以这样的方式不太适合我们传统的监督学习范式。也就是神经网络的输出会影响到神经网络的输入。
强化学习的目前应用场景有经典控制、游戏博弈、股票预测,电网优化,控制机器人等。其实还有好多好多,像推荐系统,自然语言处理,视频监控等方面都有涉及。
在强化学习中我们需要做的事情就是把序列决策过程中的所有奖励之和达到最大。
这里有两个学生提出了问题,有时我们的奖励不是及时出现的,你甚至不知道游戏是否结束了,我们是如何在序列处理过程中得到奖励,并将其加起来的呢?
回答:我们对于那种情况的定义是,我们确定一个阶段的开始与结束,然后我们为这个阶段定义奖励。事实上奖励只会在每个阶段结束的时刻出现。agents的目标就是在一个阶段中采取措施,在阶段结束的时刻,得到奖励。
我们如何来确定这个最小时间片段是多少?
回答:你的问题是如果我们的目标是基于时间的,也就是我们的目标使用最短的时间来做某件事,我们该怎么做?我们一般的做法是,每经历一个时间步长,都会有一个值为-1的奖励信号,这个奖励信号就是用来制约时间步长。我们现在的奖励就是由两部分所组成,期望奖励最大,期望时间最短。
我们有各种各样的问题,那么我们如何找到一个适合所有问题的统一框架?
将所以问题求解方法联系起来的就是:我们的最终目标是选择序列动作,最大化对未来的奖励之和。这个也就意味着,我们有时候要放弃当前的奖励,来获得未来更大的奖励和。

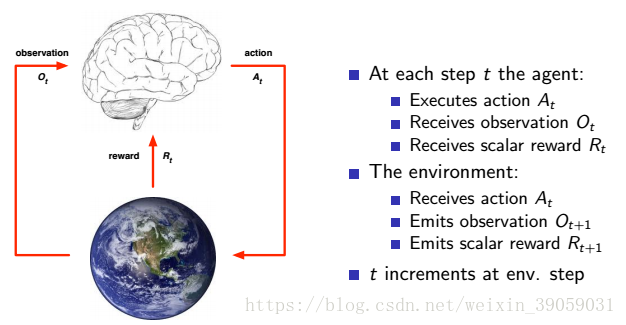
上图就是强化学习的大体框架,我们的所有算法都是加在这个大脑里面,我们也将其称之为agent。我们将这个地球称之为environment,是强化学习交互的对象。强化学习数据的来源就是通过上图交互过程中产生的数据,目前也有大批的算法是聚焦于这个数据的来源,以提高agent的学习、泛化能力。
这里有个同学又提问了,那么对于多目标优化问题,我们的智能体是如何来解决这个问题的,比如说我是应该去见我的女朋友呢,还是去帮我的老板干活?
回答:我们通过设置权重来权衡这两者之间的关系。
在agent与环境交互之后,我们得到的就是一个history,The history is the sequence of observations, actions, rewards。这个history就是目前agent所知道的东西,我们就是通过这个history数据来优化我们的算法。observation是agent所观测的东西,这其中可能有些信息是非常隐晦的,我们有时候需要一些外部算法来将其更名明显的展现给我们的智能体。就像alphago zero里面,利用卷积神经网络的卷积核来对棋盘局部特征进行处理,不仅使得agent接收的信息更加明显,同时减少计算量。
我们的算法实际上是从history到action的映射。我们的目标就是创建一个映射,算法就是从一个history到挑选下一个action的映射(我觉得这个是间接的映射,直接的映射应该是从状态到动作的),agents接下来会采取措施action完全依赖与history。环境依据history也会发生变化(这个主要是history影响了算法,算法影响了action,action的采取影响环境),这样说的话history将会决定我们获取什么样的输入,这样的话history决定了下一步的action。但是history并不是总有用,因为它通常会非常巨大。
state is the information used to determine what happens next. Formally, state is a function of history.因为state是由之前的一系列状态动作所决定的。state有很多种定义,一种是环境的全部信息我们叫做enviroment state,但是对于agent,enviroment state并不是全部可见的,我们将agent所能观测到的东西叫做observation。agent接收的信息仅仅是observation,他并不知道全部的enviroment state。我们会看到那些代表环境的信息,那也有可能是错误的信息,这种信息对于我们做出有效的决定没有好处。agent state代表的是agent内部的算法信息等,当我们agent获得一个observation后,我们通过agent state去获得下一个action。
对于多智能体系统,我们只需将其他智能体和环境都看成环境,一个大的环境,这个大的环境里面包含了一些智能体。我们并不需要改变算法的公式去处理这个问题,但是如果我们的agent与环境里面的agent有交互的话,那么问题就变得复杂起来了。
An information state被称为Markv state,也叫做信息状态。在我们使用状态表示法的时候,这些状态包含history的全部有用信息,我们能做的就是定义某个东西,这个东西具有Markov性质,这就是Markov性质。Markov性质指的是,下一时刻的状态,仅由当前状态决定,与过去的状态并没有太大的关系。
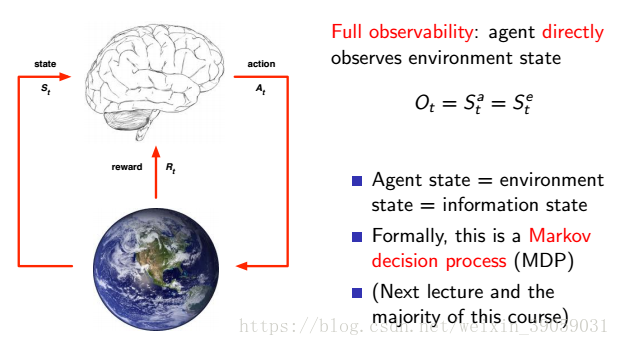
当agent state = enviroment state = information state的时候我们将其称为Markov decision process(MDP)(我对这个定义有点头大,有没有好心人指导一下):
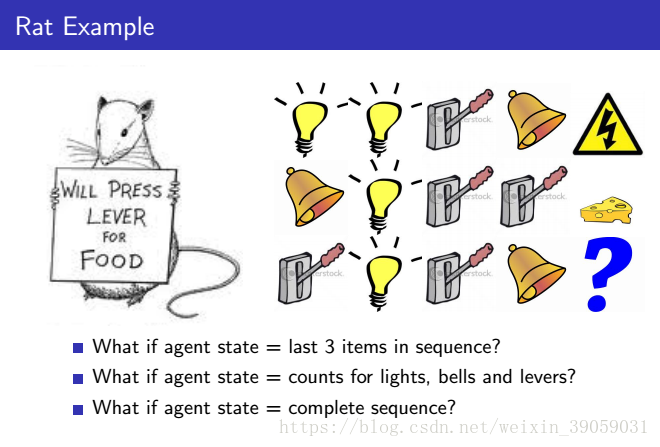
我们实际应用的过程中,我们的状态基本上都是不可完全观测的。我们很多时候所能见到的是Partial observation(部分观测环境),在这种情况下agent并不能见到环境的所有信息。比如棋牌游戏中,我们并不知道对方手里有什么牌,我们只知道自己手中的牌和已近打出去的牌,环境中还隐含了部分信息我们无法观测。这种情况称为partially observation Markov decision process(POMDP),我们的任务就是创建agent,我们需要创建的就是这种情况的Sat。我们有很多种方法去做,最简单的一种就是,我们记住每一件事。记住目前为止的每一次的观测,动作,奖励,整个的序列都将成为一个状态。之后的话,我们就可以用它了。或者我们可以创建beliefs,这是一种有问题的贝叶斯问题方法,通过计算各种状态的概率来作为新的状态。另外的一种方法就是通过循环神经网络来记住之前的state。
我们的agent包含主要的三个部分,Policy,Value, Model。policy表明了agent能够采取的行动,是一个行为函数。Value这个函数用来评价agent在某种特殊状态下的好坏、在某种状态下采取什么动作得到的预期奖励会是多少。model是用来感知环境是如何变化的,这里并不是真实的环境,而是在agent眼里面的环境,model就是用来判断环境变化的。
policy是从状态到行动措施的映射:

value函数是对未来奖励的预测

model并不是环境本身,但是有时他对于预测环境变化很有用,我们的model会学习环境的行为,然后model可以用来确定计划,model对下一步的行动很有好处,一般来说,我们的model包含两部分:transition model和reward model。transition model用于预测下一个状态,预测环境的动态变化。reward model就是我们用来预测下一个时刻的及时奖励。然而很多教程都在教一个无model的方法,这些方法根本就没用一个model,因此,model并不是我们所必需的。构建一个环境并不总是需要model这个环节。基于模型的强化学习算法利用与环境交互得到的数据学习系统或者环境模型,再基于模型进行序贯决策。无模型的强化学习算法则是直接利用与环境交互获得的数据改善自身的行为,它不会试图去理解环境,而是直接做映射。一般来讲基于模型的强化学习算法效率要高一点,但是无模型的强化学习算法更具有通用性(有些问题根本无法建立模型)。

强化学习和规划:

强化学习与规划之间的最大不同就是,我们对于环境或者求解问题是否已知。
我的微信公众号名称:深度学习与先进智能决策
微信公众号ID:MultiAgent1024
公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!本文是自己学习David Silver课程的学习笔记:原视频可以在油管或者B站上搜到。
PPT的连接如下:http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html。网速慢的话可以点击这里。
转载自原文链接, 如需删除请联系管理员。
原文链接:Lecture 1:强化学习简介,转载请注明来源!