前言
本文主要介绍MTCNN中PNet的网络结构,训练方式和BoundingBox的处理方式。PNet的网络结构是一个全卷积的神经网络结构,如下图所:

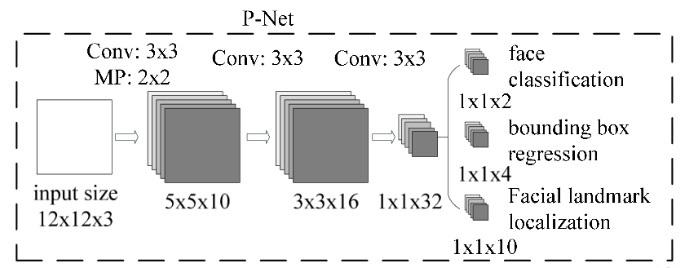
输入是一个12*12大小的图片,所以训练前需要把生成的训练数据(通过生成bounding box,然后把该bounding box 剪切成12*12大小的图片),转换成12*12*3的结构。
- 通过10个3*3*3的卷积核,2*2的Max Pooling(stride=2)操作,生成10个5*5的特征图
- 通过16个3*3*10的卷积核,生成16个3*3的特征图
- 通过32个3*3*16的卷积核,生成32个1*1的特征图。
- 针对32个1*1的特征图,可以通过2个1*1*32的卷积核,生成2个1*1的特征图用于分类;4个1*1*32的卷积核,生成4个1*1的特征图用于回归框判断;10个1*1*32的卷积核,生成10个1*1的特征图用于人脸轮廓点的判断。
模型代码
PNet是一个全卷积网络,所以Input可以是任意大小的图片,用来传入我们要Inference的图片,但是这个时候Pnet的输出的就不是1*1大小的特征图了,而是一个W*H的特征图,每个特征图上的网格对应于我们上面所说的(2个分类信息,4个回归框信息,10个人脸轮廓点信息)。W和H大小的计算,可以根据卷积神经网络W2=(W1-F+2P)/S+1, H2=(H1-F+2P)/S+1的方式递归计算出来,当然对于TensorFlow可以直接在程序中打印出最后Tensor的维度。相应的TensorFlow代码如下:
with slim.arg_scope([slim.conv2d],
activation_fn=prelu,
weights_initializer=slim.xavier_initializer(),
biases_initializer=tf.zeros_initializer(),
weights_regularizer=slim.l2_regularizer(0.0005),
padding='valid'):
net = slim.conv2d(inputs, 10, 3, stride=1,scope='conv1')
net = slim.max_pool2d(net, kernel_size=[2,2], stride=2, scope='pool1', padding='SAME')
net = slim.conv2d(net,num_outputs=16,kernel_size=[3,3],stride=1,scope='conv2')
net = slim.conv2d(net,num_outputs=32,kernel_size=[3,3],stride=1,scope='conv3')
conv4_1 = slim.conv2d(net,num_outputs=2,kernel_size=[1,1],stride=1,scope='conv4_1',activation_fn=tf.nn.softmax)
bbox_pred = slim.conv2d(net,num_outputs=4,kernel_size=[1,1],stride=1,scope='conv4_2',activation_fn=None)
landmark_pred = slim.conv2d(net,num_outputs=10,kernel_size=[1,1],stride=1,scope='conv4_3',activation_fn=None)
转载自原文链接, 如需删除请联系管理员。
原文链接:MTCNN人脸检测---PNet网络训练,转载请注明来源!