声明:文本非原创,只是翻译,原文链接如下:
https://simonschreibt.de/gat/renderhell-book2/
Render Hell – Book II


本文是 “Render Hell” 系列文章的第二篇。

Pipeline 详解
关于本篇文章,我收到的大多数积极反馈是:非常漂亮的演示说明,但是你的 Pipeline 已经是6年前的了!最初我一直不明白这句话是什么意思,直到 Christoph Kubisch 加入到我的 Render Hell 创作中来,我才明白这句话的含义。他是一名就职于 NVIDIA 的技术开发工程师,无论我有什么样的问题,他都会为我一一解答。请相信我,我的问题实在是太多了!😃
我们的讲解都是基于 NVIDIA 架构的,因为 Christoph 就在 NVIDIA 工作。因此我希望你们不要把这篇文章当作是 NVIDIA 的软文,我俩都有解说事物原理的激情,而且我真的很高兴能有个人来帮助我理解那些技术知识。
请注意,我们省略并简化了一些细节内容。
关于 Pipeline 有两点需要做如下说明,虽然这两点在 Book I 中并没有明显的错误描述,但是可能还是不够清晰:
1. 并不是所有的事情都是由 “微小” 的 GPU Core 来完成的!
2. 可以允许多条 Pipeline 同时运行!
接下来我将详细说明这两点,希望你能喜欢!
1. 并不是所有的事情都由 “微小” 的 GPU Core 来完成的
在之前的 Pipeline 示例中,看上去每个 Pipeline 阶段都是由 GPU Core 来完成的 —— 其实并非如此!实际上大多数的任务都不是由它们完成的。在上一篇 “1. 拷贝数据到系统内存” 这一小节中,你已经看到,要想把数据给到 Core 还需要一些必要的组件。那么 Core 到底做了哪些事情呢?
我们一起来看看下面这个家伙吧:
一个 Core 可以接收命令和数据,然后通过计算浮点(FP)或整型(INT)数据来执行命令。因此你可以这么认为:Core 可以计算像素和顶点(也可能是其它的计算,比如物理计算,但这里还是让我们把重点放在图形渲染上面吧)。

其它那些重要的事情,例如分配渲染任务、曲面细分、剔除和准备像素着色器的片元、深度测试以及将像素写入 FrameBuffer,这些都不是由 Core 来完成的,而是由 GPU 内部专门的、不可编程的硬件模块来完成的。
好了,了解了这一点之后,让我们继续讨论下一个重点,一个我必须要澄清的重点:
2. 允许多条 Pipeline 同时运行
首先,我会用一个简短的例子来告诉你这个小标题的含义,如果你看了之后还是无法满足你的求知欲,我会再给你一个更详细的讲解。但在那之前,还是让我们先快速回顾一下:
假如我们只有一个 GPU Core,我们能用它来计算什么?
回答正确:什么也计算不了!因为 GPU Core 是需要别人分配任务给它的。而负责分配任务的人就是 Streaming Multiprocessor(SM,流处理器簇),它可以用来处理一个着色器上的顶点流/像素流。OK,有了 SM 和 Core,我们就可以计算了,但是每次只能计算一个顶点/像素:

当然了,如果我们增加 Core 的数量,就可以在同一时刻计算多个顶点/像素了,但前提是这些顶点和像素都必须属于同一个着色器!

以上这些在我上一篇介绍 Pipeline 的时候其实就已经讲过了!但是现在让我们来点更有意思的:如果我们再添加一个 SM,让它们各自管理一半的 Core,将会是什么样的结果呢?

这样我们既可以并行的计算顶点/像素,又可以同时处理2个着色器了!这意味着,我们可以同时运行2个不同的像素着色器,或者同一时刻运行一个顶点着色器和一个像素着色器!

以上这些简单的演示只是想让你感受一下,不同的硬件模块之间都是并行工作的,而真实的 Pipeline 其实会比我上一篇描述的更加灵活多变。
还没满足你的好奇心?那就和我一起深入到更多的细节里去吧!
3. 深入探究 Pipeline 阶段
3.1 简介
首先:为什么我们需要一个灵活的、可并行的 Pipeline?原因就是,你无法预料你会碰到多大的负载。尤其是曲面细分,可能会比上一帧突然多出10万个多边形出来。因此,你需要一个灵活的 Pipeline 来应对各种不同的负载情况。
别担心!
当你看到下面两幅图时,千万不要害怕(就像我当初在维基百科上见到文字间的公式一样)!没错,这东西并不那么好理解,甚至复杂的图表只能显示出程序猿需要知道什么,并且隐藏了大量的“真正”复杂的东西。我把这两幅图放在这里,仅仅只是为了让你大致明白这个玩意儿究竟有多复杂 😃。
图片来源:http://www.legitreviews.com/

下图截取自 Christoph Kubisch 的文章《Life of a triangle》,它展示了 GPU 在结构化图形系统中的部分工作原理。
图片来源:Christoph Kubisch 的文章《Life of a triangle》

现在,我希望你能对 Pipeline 的复杂性有个大致的印象,并且能够意识到接下来的讲解是有多么简单。那就让我们一起来看看整个 Pipeline 的详细流程吧!
3.2 App 阶段
一切从这里开始,应用程序或游戏 App 告诉驱动程序它们想要渲染一些东西。

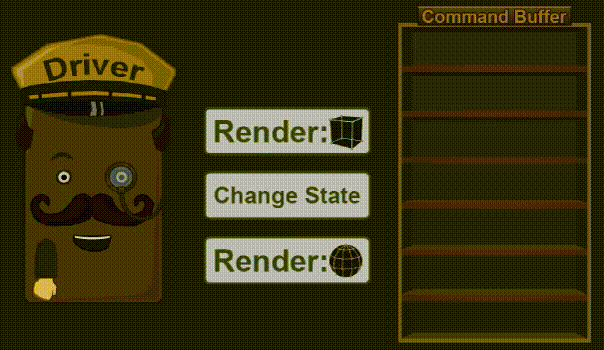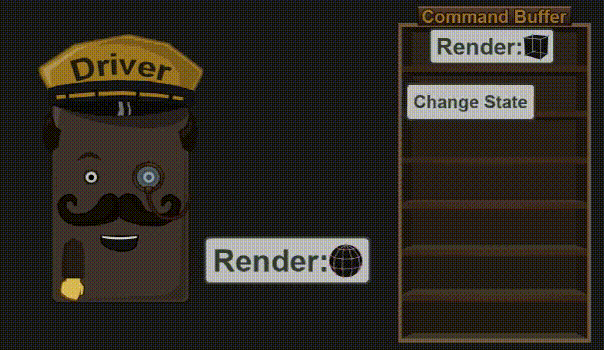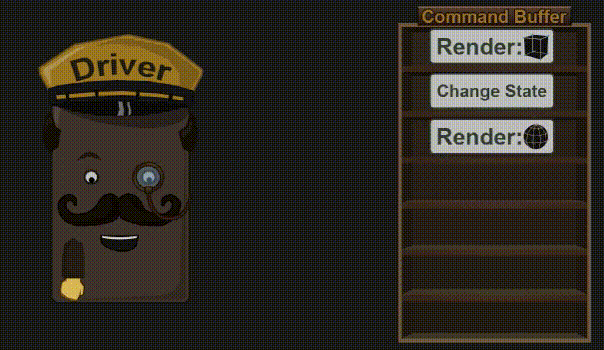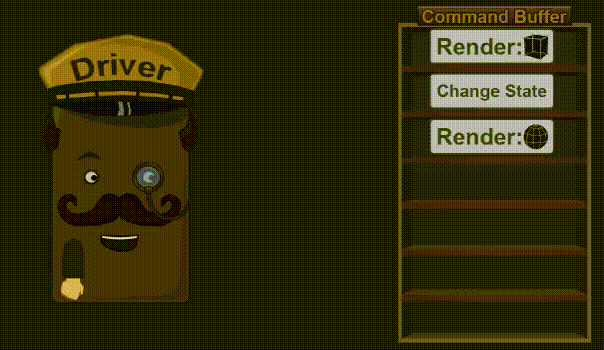
3.3 Driver 阶段
驱动程序接收来自 App 的命令,然后将它们放入 Command Buffer 中(在上一篇已经介绍过了)。不久之后(或者是程序猿强制执行),这些命令就被送进 GPU 里去了。
注意: 驱动程序可能会造成性能瓶颈,详见 Book III 中 “1. 大量的 Draw Call” 一节。
3.4 读取命令
现在我们来到显卡内部,Host 接口会从 Command Buffer 中读取命令,以便后续执行它们。
3.5 获取数据(Data Fetch)
发送给 GPU 的命令,有的自身携带数据,有的本身则为一条拷贝数据的指令。GPU 通常有一个专用引擎,用来处理从 RAM 到 VRAM 的数据拷贝,反向传输也是一样的。这些数据可以是用来填充顶点缓冲区、纹理或其它着色器参数。我们看到的一帧画面内容通常是从发送一些摄像机矩阵参数开始的。

重点
- 虽然我这里采用几何图形来表示数据,但实际上我们只是在讨论顶点列表(顶点缓冲区)。很长一段时间,渲染过程并不关心最终的模型。相反,大多数情况下,渲染过程只不过是在处理单个顶点或像素。
- 只有当 VRAM 中找不到所需的纹理时,才需要执行拷贝动作。
- 如果顶点数据经常需要被访问,那么它们可以像纹理那样一直呆在 VRAM 中,而不用每次执行 Draw Call 时都去拷贝它们。
- 如果顶点数据经常发生变化,那么它们可以一直呆在 RAM 里 (而非 VRAM),这样 GPU 可以直接将它们从 RAM 读取到 Cache 中。
现在所有的原材料都准备就绪了,Gigathread 引擎便开始发挥它的作用了。它为每个顶点/像素创建一个线程,并将它们封装成一个包,NVIDIA 把这个包叫做:线程块(Thread Block)。Gigathread 引擎还会为曲面细分后的顶点、几何着色器(后面会讲到)创建额外的线程。最后,线程块被分发到各个 SM 手里。

3.6 获取顶点(Vertex Fetch)
SM 其实是各种不同硬件单元的集合,其中一个就是几何处理引擎(Polymorph Engine)。为了简单起见,我把他们描绘成单独的个体 😃 。几何处理引擎找到所需的顶点数据并将其复制到 Cache 中,以便 Core 能够更快地访问它们。在 Book I 中已经解释过为什么需要将数据复制到缓存中了,这里就不再赘述。
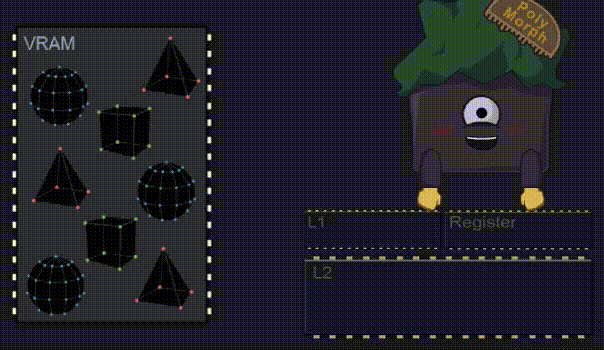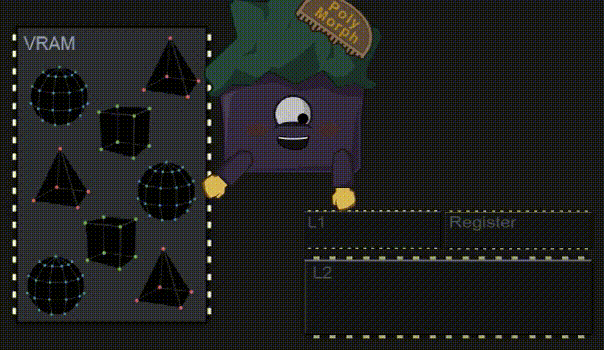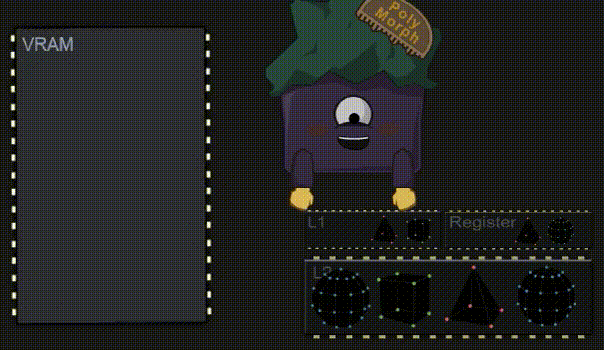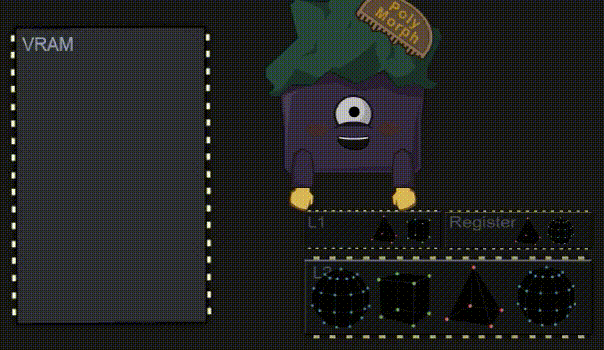
3.7 执行着色程序
SM 的主要目的是执行 App 开发人员编写的程序代码,也被称为 着色器(Shader)。着色器的种类有很多,但每种都可以在任何一个 SM 中运行,并且它们都遵循相同的执行逻辑。
接下来 SM 会将它从 Gigathread 引擎那收到的大线程块,拆分成许多更小的堆,每个堆包含32个线程,这样的堆也被称为:Warp。一个 Maxwell 架构的 SM 最多可以容纳64个 Warp。在我的示例中,以及 Maxwell 架构的 GPU 中,有32个专用的 Core 来处理32个线程。
然后一个 Warp 就被拿去工作了。此时,硬件应将所有需要的数据加载到寄存器中,以便 Core 可以用它们来工作。我这里对演示做了一点简化:Maxwell 的流处理器(SP)一般有4个 Warp 调度器,每个调度器可以处理一个 Warp,并管理 SM 上剩余的 Warp。

真正的工作现在才开始!GPU Core 本身看不到所有的 Shader 代码,它们只能同一时刻看见1条指令。它们处理完当前指令后,SM 会给他们发送下一条指令。所有的 Core 都执行相同的指令,却作用于不同的数据(顶点/像素)。不可能存在说一部分 Core 在执行指令 A 的时候,另一部分 Core 却在执行指令 B。这种执行机制被称为 锁步(lock-step)。

如果你的 Shader 代码中有 IF 语句,锁步机制将变得尤为重要。

IF 语句可以让一部分 Core 执行左边的代码,而另一部分 Core 则执行右边的代码,但绝不允许这两部分 Core 同时执行(这点前面已经说过了)。首先,左侧代码在被执行的时候,负责执行右侧代码的 Core 则处于“休眠状态”。等左侧的 Core 执行结束后,右侧的 Core 才开始执行。Kayvon 则在视频 “What about conditional execution?” 中(43:58 时间点)解释了这一行为。
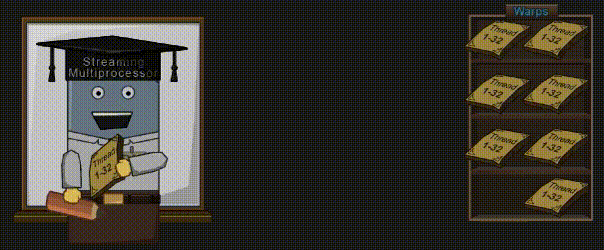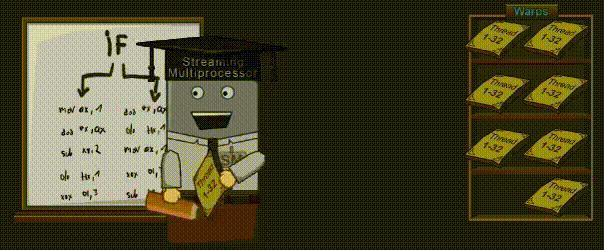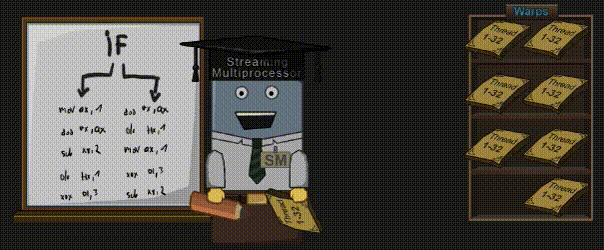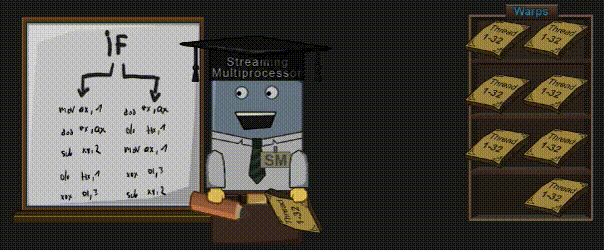
译者注:GPU 中的 IF 条件不同于 CPU。在 CPU 中,IF 条件只会执行一条分支;而在 GPU 中,IF 条件很有可能两条分支都执行。可以参考知乎上的回答《Shader中的条件分支能否节省shader的性能?》。
在我给的例子中,16个像素/顶点是可以满足要求的,但是也很有可能会出现这样的 IF 条件:只有1个像素/顶点需要被计算,而其它31个 Core 都会被屏蔽掉。这种情况也同样会发生在循环语句中,如果有一个 Core 在循环中呆太久,就会导致所有其它的 Core 都处于空闲状态。这种现象也被称为 Divergent Thread(分歧线程),应该尽量避免这种情况发生。理想情况下,我们希望 Warp 中的所有线程都满足 IF 条件的同一侧分支,这样我们就能完全跳过另一侧的分支了。
但是明明同一时刻只有几个 Core 可以工作,为什么还要让 SM 容纳 64 个 Warp 呢?这是因为有时候为了等待某些数据就绪,你不得不停下来。比如说,我们需要通过法线纹理贴图来计算法线光照,即使该法线纹理已经在 Cache 中了,访问该资源仍然会有所耗时,而如果它不在 Cache 中,那就更加耗时了。用专业术语讲就是 Memory Stall(内存延迟),关于这点 Kayvon 给出了详尽的解释。与其什么事情也不做,不如将当前的 Warp 换成其它已经准备就绪的 Warp 继续执行。

上面的讲解有点简单了。现代的 GPU 架构不再像当初那种,只允许 Streaming Processor (SP) 在一定时间内只处理一个 Warp 。看看 这张 基于 Maxwell 架构的 SP(SMM)图片:一个 SM 可以访问四个 Warp 调度器,每个调度器控制32个 Core,这使得它能够完全并行的处理4个 Warp。多线程工作状态的记录本是独立保存的,并以 SM 可以并行运行的线程数来表示,就像上面提到的那样。

正如 Guohui.Wang 所指出的,不仅仅是在等待内存时需要切换调度器,其它情况也需要切换调度器:
因为在 Maxwell 中可以同时运行4个以上的 Warp,每个 Warp 调度器可以在一个时钟周期内对 Warp 发起两次指令传输。在这种情况下,每个时钟周期内有多达4个 Warp 可以执行它们新的指令(假设至少有4个 Warp 已经准备就绪)。然而,我们同样也有指令级的并行处理。也就是说,当有4个 Warp 正在执行指令的时候(通常需要持续10-20个时钟周期),下一批4个 Warp 可以在下一个时钟周期到来时接受新的指令。因此,如果资源可用,则可能会有4个以上的 Warp 同时运行。实际上,在 GTC2013 大会上的一个 CUDA 优化视频里讲到,在常用 case 中推荐使用30个以上的有效 Warp,这样才能确保 Pipeline 的满载利用率。因此,您可能需要修改一下此处的描述,以表明会有多个(超过4个)Warp 同时运行,以防别人误认为4个调度器只能容纳4个并行的 Warp。
—— Guohui Wang
但是我们的线程到底做了什么事情呢?举个栗子,顶点着色器!

3.8 顶点着色器(Vertex Shader)
顶点着色器用于处理单个顶点,并根据程序猿的需要对其进行修改。不同于常用的软件(如邮件程序),你运行一个程序,并交给它一堆需要处理的数据(如处理所有的邮件),当你运行一个顶点着色程序来处理每个顶点时,它会在 SM 管理的每个线程中运行。
我们的顶点着色器会根据你的需要,对顶点及其相关参数(如位置、颜色、UV坐标)进行转换:
个别 Pipeline 流程只会在用到曲面细分技术的时候才会被执行,如果你的游戏程序不会用到曲面细分技术,你可以选择跳过接下来的 3.9 ~ 3.12 章节。
3.9 面片装配(Patch Assembly)
直到这里,我们看到的都是单个的顶点。当然,它们都是按照特定的顺序由程序猿发出的,但我们并没有把它们当作一个组,而是当作一个个相互独立的点来处理。以下几个小节讨论的步骤仅在使用 曲面细分着色器 时才会被执行。第一步是根据各个顶点创建 面片(Patch),这样就可以对它们进行细分并添加几何细节了。具体需要多少个顶点来组装成一个面片是由程序猿来决定的,最大的个数是,猜猜看,32个。
在 OpenGL 中,这个阶段被称为 Patch/Primitive Assembly,而在 DirectX 中,只有 Patch Assembly(Primitive Assembly 后面会讲到)。有关 Patch/Primitive Assembly 更多详细内容,请参考[a57]。

3.10 外壳着色器(Hull Shader)
外壳着色器使用顶点来计算细分因子,这些顶点全部来源于前面创建的单个面片,而计算得出的细分因子大小,则取决于模型到摄像机的距离。由于硬件只能细分三种 基本形状(四边形、三角形或一系列直线),因此 shader code 中还会指明当前细分器应该使用哪种基本形状。最终的结果就是,我们得到了不只一个细分因子,而且它们是为形状的每一个外侧和一个特殊的“内侧”计算的。为了后续能够创建更为重要的几何图形,外壳着色器还要为专门处理位置信息的域着色器计算输入值。
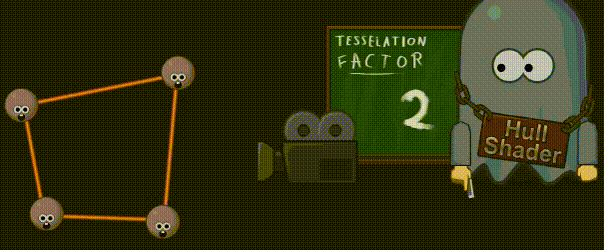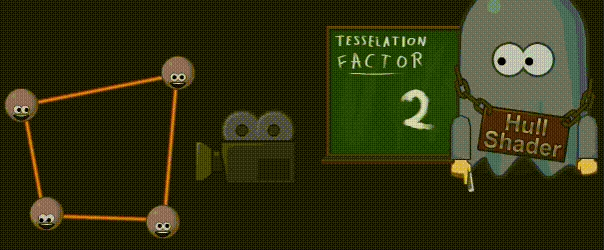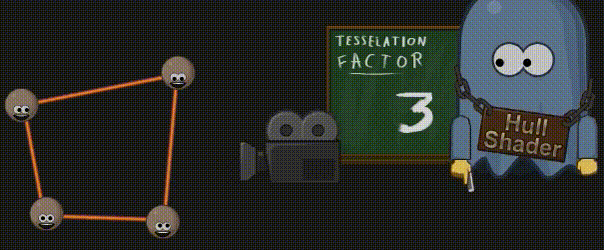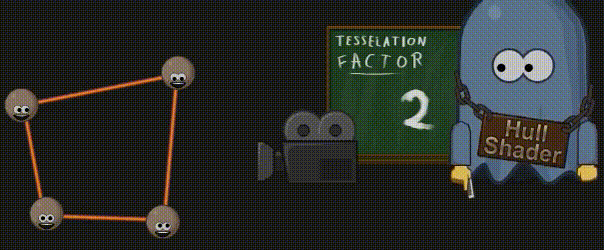
3.11 曲面细分(Tessellation)
现在我们清楚了要使用哪种基本形状来进行细分,以及要细分成多少块 —— 几何处理引擎(Polymorph Engine)使用这些信息来开展真正的细分工作。最终我们得到了许多新的顶点,这些顶点再次被送回给 Gigathread 引擎,在 GPU 上进行分发,并最终交由域着色器处理。有关着色器阶段的更多详细信息,请参见 [a55] 和 [a79]。
在这里你可以找到关于 三角形细分(Triangle Tesselation)和 四边形细分(Quad Tesselation)的详细文章。
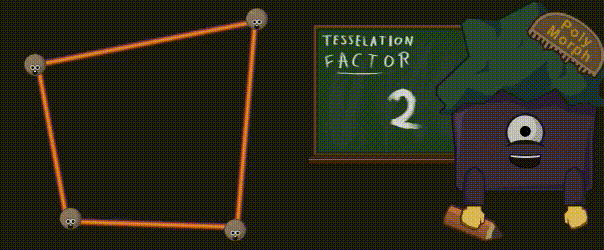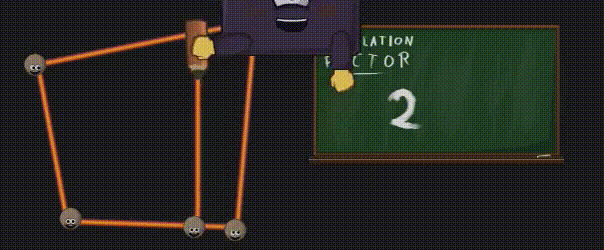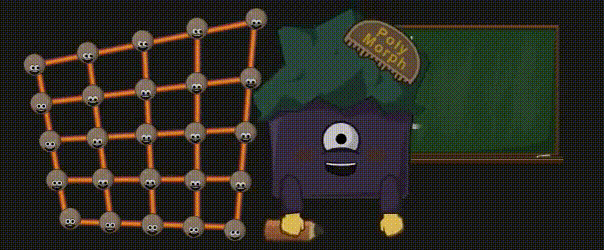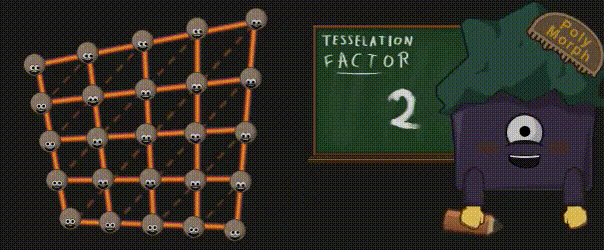
您可能会问,为什么不直接将几何图形的所有细节都放入模型中呢?这是因为有两个原因:首先,您可能还记得,与纯粹的计算相比,访问内存是有多慢。因此,与其读取所有这些额外的顶点以及它们全部的属性(位置、法线、UV坐标等),还不如使用较少的数据(面角顶点 + 替代逻辑或纹理,支持 Mipmap、压缩 …)来生成它们。其次,通过曲面细分技术,你可以根据摄像机的距离来调节某些细节,所以你会非常灵活。否则,我们可能会计算大量的顶点,而这些顶点所在的三角形甚至最终都不可见(因为太小或不在显示区域内)。
3.12 域着色器(Domain Shader)
现在到了计算细分顶点的最终位置的时候了,如果程序猿想使用置换贴图(displacement map),它就会在这里生效。域着色器的输入来自外壳着色器的输出(例如面片顶点),以及来自细分的重心坐标。有了重心坐标和面片顶点,你就可以计算新的顶点位置,然后对它应用置换贴图了。与顶点着色器类似,域着色器计算出的数据会被传递到下一个着色器阶段,该阶段要么是几何着色器(Geometry Shader)(如果被激活的话),要么是片元着色器(Fragment Shader)。
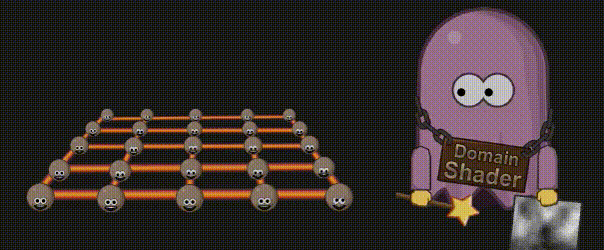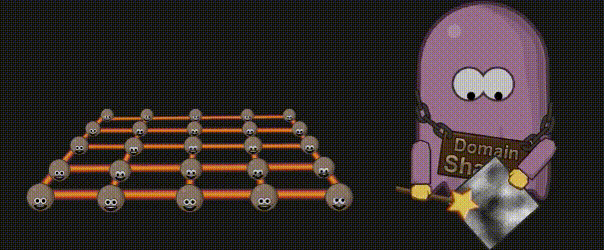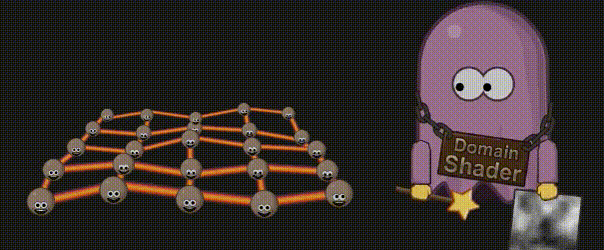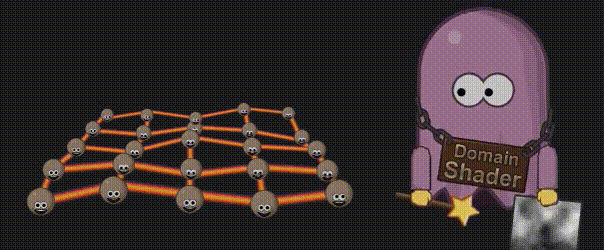
3.13 图元装配(Primitive Assembly)
来到几何 Pipeline 的末端,我们收集顶点,用于装配我们的图元:三角形、直线或点。这些顶点要么来自顶点着色器,要么来自域着色器(如果曲面细分被激活的话)。
我们所处的模式(三角形、直线或点)是由发起本次 Draw Call 的应用程序来决定的。通常,我们只需要将图元传递给最终的处理单元并进行光栅化就可以了,但还有一个可选的阶段也会用到这些信息,它就是几何着色器。

3.14 几何着色器(Geometry Shader)
几何着色器作用于最终的图元。与外壳着色器类似,它获取图元的顶点作为输入。它可以修改这些顶点,甚至生成一些新的顶点。它还可以改变最终的图元模式。例如,将一个点转换为两个三角形,或立方体的三个可见边。
但是,我们并不提倡创建大量新的顶点或三角形,细分的工作最好还是留给细分着色器去处理。几何着色器存在的意义是相当特殊的,因为它是图元光栅化之前的最后一个准备环节,比如它在当前的 体素化技术(voxelization techniques)中起着关键作用。
在这里你可以找到如何编写和使用几何着色器的优秀示例,而在这里还可以找到关于 OpenGL Pipeline 很好的介绍。

3.15 视口变换(Viewport Transform)和裁剪(Clipping)
直到这里,程序猿所有的操作使用的似乎都是二次空间(我想这样做更简单/更快),但现在到了该把画面内容适配到实际显示分辨率(或游戏呈现的窗口)的时候了。有关此操作的更多信息,请参见 这篇文章 的 “Viewport Transform/Screen Mapping” 小节。
同样的,如果三角形超出了镜头的某个安全边界(保护带),那么它也会被裁剪,我们将这种行为称作 保护带裁剪(Guard Band Clipping),你可以在 这里 和 这里 找到更多相关信息。之所以要裁剪,是因为光栅化执行单元只能处理其工作区域内的三角形:

3.16 三角形之旅(Triangles Journey)
其实它在 Pipeline 中并不是一个独立的步骤,但我发现它其实蛮有意思的,所以我就给它单独设立了章节。
现在我们有了顶点确切的位置、阴影等信息,在我们开始“绘制”这些三角形之前,必须得先找出屏幕上哪些像素处于三角形区域内,这个工作则是由 光栅器 来完成的。这里需要强调一下,如果这个三角形非常大,那么会有多个可用的光栅器在同一个三角形上同时工作。否则,也就意味着只有一个光栅器处于工作状态,而其他的光栅器则处于空闲状态。
因此,每一个光栅器都负责屏幕上特定的几个区域,如果一个三角形经确认属于某个特定区域(通过三角形的边界框(bounding box)来检测),那么它就会被发送给负责该区域的光栅器去处理。

3.17 光栅化(Rasterizing)
光栅器收到他要处理的三角形,首先快速检查该三角形是否面向镜头。如果不是,那就直接扔掉(背面剔除,Backface Culling)。如果三角形是“有效的”,则光栅器会计算连接顶点的边(edge setup),并查看哪些像素四边形(2×2像素)在三角形内,以此来创建 预像素 / 片元。
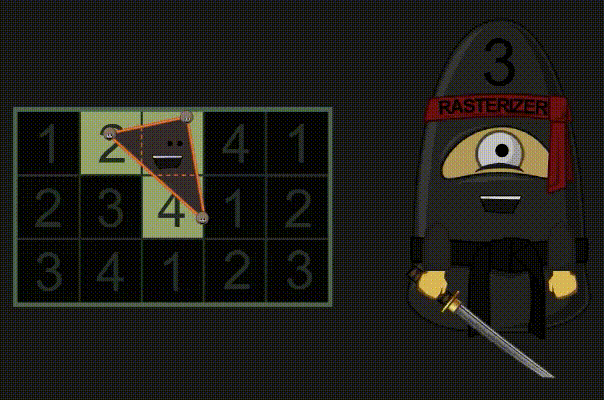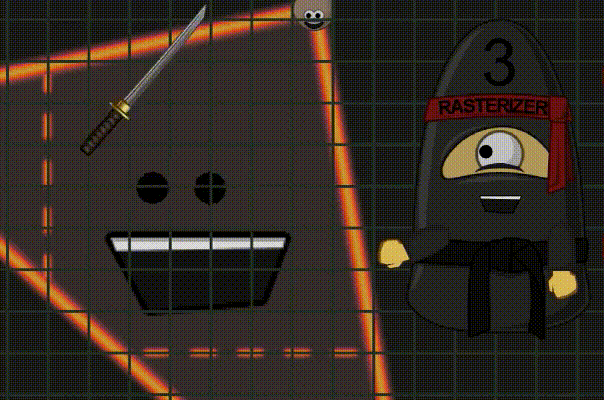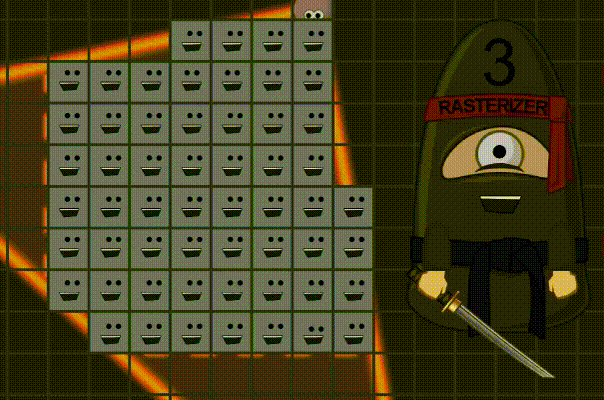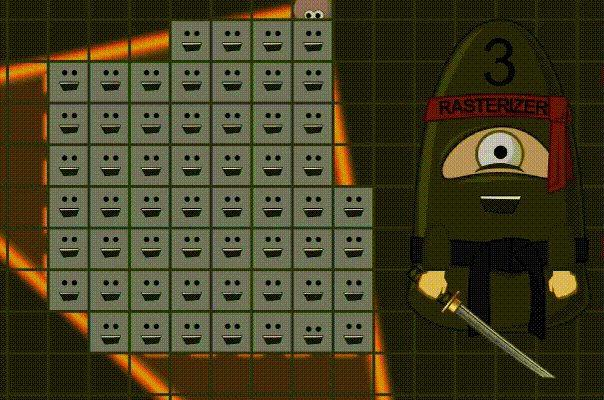
如果你对光栅化和微三角形(micro-triangles)真的很感兴趣,你一定要看看这个 PPT,还有 这一篇 不错的介绍。
光栅化引擎总是以2×2像素为单位进行工作,这会使渲染过程效率低下,详情参见 Book III。
创建完预像素/片段之后,还要检查它们是否真的可见(或是否被其它已渲染的物体挡住):
光栅器所产生的像素会被送到 Z-cull (Z轴剔除)单元。Z-cull 单元拿到一个像素块,并将该块中像素的深度与 FrameBuffer 中已有像素的深度进行比较,完全位于 FrameBuffer 像素后面的像素块将从 Pipeline 中剔除掉,从而消除进一步像素着色工作的需要。
—— NVIDIA GF100 白皮书
3.18 像素着色器(Pixel Shader)
生成预像素/片元后,我们就可以对它们进行“填充”了。对于每个预像素/片元,都会生成一个新的线程,并再次分发给所有可用的 Core(就像处理所有顶点那样)。
“同样,我们对32个像素线程进行批处理,更准确的说是8个2×2像素块,它始终是像素着色器工作的最小单位。”
当 Core 完成他们的工作后,会将结果写回到原来的寄存器中,并将寄存器的结果写入缓存以便进行最后一步:光栅输出(ROP)。

3.19 光栅输出(Raster Output)
最后一步是由光栅输出单元来完成的,该单元会将最终的像素数据(刚从像素着色器那得到的)从二级缓存搬运到 VRAM 中的 FrameBuffer 里。以 GF100 为例,它有48个这样的 ROP 单元,我是根据它们彼此非常靠近来演示数据流的(从二级缓存到 VRAM):
“[…] 二级缓存和 ROP 组是紧密耦合在一起的 […]”
—— NVIDIA GF100 白皮书
除了搬运像素数据,ROP 还负责 像素混合(Pixel Blending)、抗锯齿(Anti Aliasing) 信息汇报以及 “原子操作(Atomic Operation)”。
多么奇妙的一次旅行啊!我花了很长一段时间才把所有的信息汇集到一起,希望这篇文章能够对你有所帮助。

本篇到此结束。
转载自原文链接, 如需删除请联系管理员。
原文链接:Render Hell —— 史上最通俗易懂的GPU入门教程(二),转载请注明来源!