论文:Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
论文链接:http://openaccess.thecvf.com/content_cvpr_2017/papers/Fu_Look_Closer_to_CVPR_2017_paper.pdf
Recurrent Attention Convolutional Neural Network(RA-CNN)是CVPR2017的Oral文章,针对细粒度(fine-grained)的分类。作者提出的RA-CNN算法不需要对数据做类似bounding box的标注就能取得和采用类似bounding box标注的算法效果。在网络结构设计上主要包含3个scale子网络,每个scale子网络的网络结构都是一样的,只是网络参数不一样,在每个scale子网络中包含两种类型的网络:分类网络和APN网络。因此数据流是这样的:输入图像通过分类网络提取特征并进行分类,然后attention proposal network(APN)网络基于提取到的特征进行训练得到attention区域信息,再将attention区域crop出来并放大,再作为第二个scale网络的输入,这样重复进行3次就能得到3个scale网络的输出结果,通过融合不同scale网络的结果能达到更好的效果。多scale网络的最大优点在于训练过程中可以逐渐聚焦到关键区域,能更加准确,因此多scale网络是本文的第一个亮点。另外针对分类网络和APN网络设计两个loss,通过固定一个网络的参数训练另一个网络的参数来达到交替训练的目的,文中也说明了这二者之间本身就是相互促进的,因此这两个子网络的设计及其交替训练方式是本文的第二个亮点。要说第三个亮点的话,那应该就是不需要bounding box的标注信息了,因为这种细粒度图像的bounding box标注会比普通的bounding box更难,更加需要专业知识,因此无监督式地寻找关键区域是比较理想的方向。总的来讲这篇文章的网络结构和训练策略设计得非常巧妙,不愧是CVPR2017的oral。
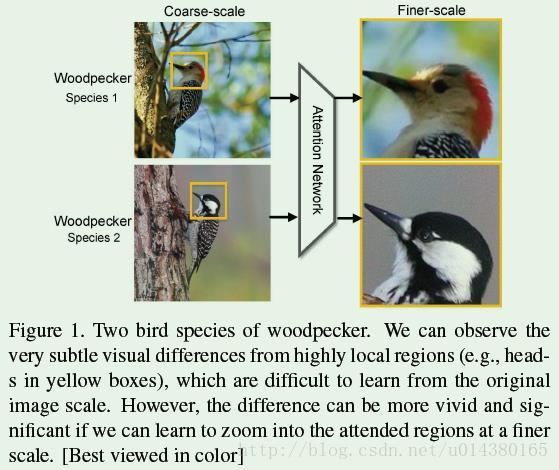
细粒度(fine-grained)图像分类是近几年比较火的领域,可以看FIugre1中的例子,虽然都是啄木鸟,但是要细分不同的品种,可以看出这两类之间的特征差异非常小。因此细粒度图像分类的难点主要包含两方面:1、discriminative region localization;2、finegrained feature learning from those regions。也就是说一方面要能准确定位到那些关键区域,另一方面要能从那些关键区域中提取有效的信息,在作者看来这两方面是相互促进的,所以在训练网络的时候采取了交替训练的策略。目前关于这样的区域定位方法主要分为两种:监督式和非监督式。监督式也就是对训练数据标注bounding box信息,类似object detection算法;非监督式的就是通过网络去学习这些区域信息,训练数据没有bounding box信息。

其他一些细粒度图像算法一般是怎么做呢?主要分两步,第一步是采用无监督或者有监督(比如常见的object detection算法)的算法检测出指定的区域。第二步是从第一步检测到的区域中提取特征用于分类。原文如下:Previous research has made impressive progresses by introducing partbased recognition frameworks, which typically consist of two steps: 1) identifying possible object regions by analyzing convolutional responses from neural networks in an unsupervised fashion or by using supervised bounding box/part annotations, and 2) extracting discriminative features from each region and encoding them into compact vectors for recognition. 但是人为标定的区域(region)不一定是最适合模型分类的区域,另外作者认为这两步之间是有相互促进关系的,原文如下:We found that region detection and fine-grained feature learning are mutually correlated and thus can reinforce each other,因此有了RA-CNN网络。
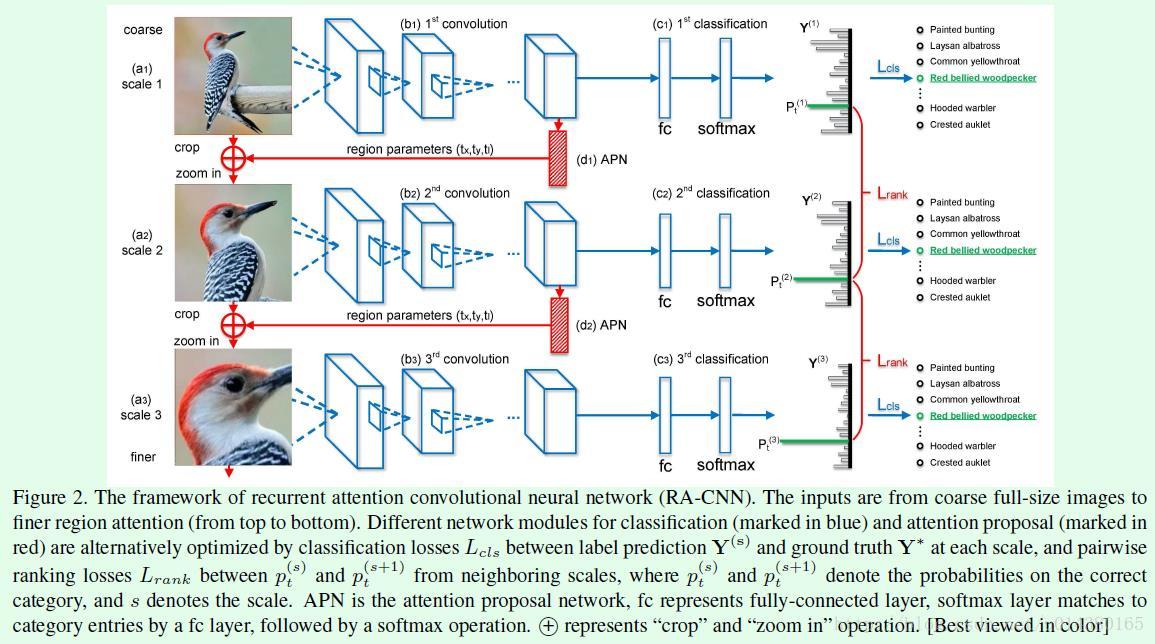
Figure2是以3个scale为例子的网络结构(可以根据需要叠加多个scale)。(a1)、(a2)、(a3)分别表示3个不同scale的网络。(b1)、(b2)、(b3)分别表示3个不同scale网络的卷积层,这些卷积层实现的就是从输入图像中提取特征,也就是现在CNN网络干的主要的活,这三个网络的结构是一样的。根据提取到的特征,一方面传给全连接层和softmax层去预测该图片的类别概率,另一方面通过APN网络(d1)、(d2)得到区域信息。这两个方面的操作也就是文中说的multi-task,一个task做分类,另一个task做区域检测,听起来是不是觉得和object detection类的算法很像,其实本质是一样的,只不过这里的区域检测不是监督学习,也就是说不需要bounding box的标注信息,而是通过end-to-end训练得到的,另外这两个task的损失函数设计也比较重要。文中的公式1对应task1:
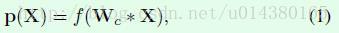
公式2对应task2:
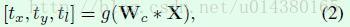
这里的Wc就是指的(b1)或(b2)或(b3)网络的参数,也就是一些卷积层、池化层和激活层的集合,用来从输入图像中提取特征,Wc*X就是最后提取到的特征。然后f()函数(task1)是全连接层和softmax层,用来将学习到的特征映射成类别概率,也就是p(X)。g()函数也就是APN网络(task2)可以用两个全连接层实现,其中最后一个全连接层的输出channel是3,分别对应tx、ty、tl。这里因为假设检测出来的区域都是正方形,所以得到的tx和ty表示区域的中心点坐标,tl表示正方形区域边长的一半(为什么是一半后面会解释)。
假设原始图像的左上角是坐标系的起点,用符号tl表示左上角这个点,用符号br表示右下角这个点,那么根据APN网络得到的tx、ty和tl可计算得到crop得到的区域的左上角点和右下角点的x轴(tx(tl)、tx(br))和y轴(ty(tl)、ty(br))坐标分别如公式3所示。所以前面之所以tl表示边长的一半是为了公式3中的式子可以少写1/2。
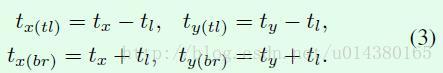
定义好了坐标关系,就可以用一个mask M和输入图像X做element-wise multiplication来得到crop后的区域。这个过程可以用公式4来表示:
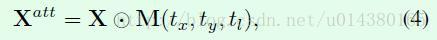
其中Mask的公式如下,后面会介绍为什么要用这样的函数。
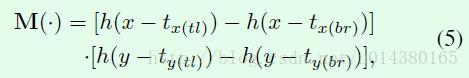
在M()函数中的h()就是sigmoid函数(和文中说的logistic function是一个意思,logistic function这个名称来源于逻辑回归):
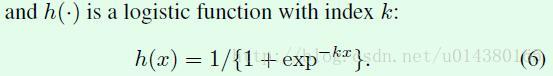
公式6比较好理解,因为就是常见的sigmoid函数。首先k这个参数可以设定成一个较大的正整数(实验中设置为10),这个时候sigmoid函数就很像一个阶跃函数。这样当-kx很大时(比如正无穷),分母也是趋于无穷大的,这个时候h(x)接近于0;当-kx很小时(比如负无穷),分母的后一半是趋于0的,这样整个分母就趋于1,这样h(x)接近于1。因此当x在tx(tl)和tx(br)之间时,h(x-tx(tl))-h(x-tx(br))就趋近于1-0=1,y轴同理。这样的话只有当x在tx(tl)和tx(br)之间且y在ty(tl)和ty(br)之间时,M()才趋于1*1=1,其他情况都是趋于1*0或0*1或0*0。
那么为什么要用这个稍微复杂的mask函数来做crop,而不是直接根据坐标和边长信息生成一个0-1的mask,答案是:end-to-end优化训练需要这样的连续函数,原文是这么说的:To ensure the APN can be optimized in training, we approximate the cropping operation by proposing a variant of two-dimension boxcar function as an attention mask. The mask can select the most significant regions in forward-propagation, and is readily to be optimized in backward-propagation due to the properties of continuous functions.
确定好了如何crop的策略,接下来就是对crop后的区域放大,文中介绍采用的是双线性插值(bilinear interpolation),公式如下:
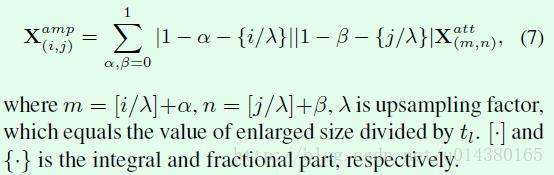
接下来看看损失函数。本文的损失函数主要包含两部分,如公式8所示。一部分是Lcls,也就是分类的损失,Y(s)表示预测的类别概率,Y*表示真实类别。Lrank表示pairwise ranking loss,可以看FIgure2中红色的大括号,第一个scale网络和第二个scale网络构成一个Lrank,同样第二个scale网络和第三个scale网络构成另一个Lrank。在训练这个网络的时候采取的是损失函数交替训练的策略,后面会详细介绍。
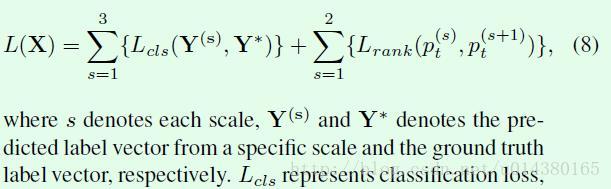
Lrank的公式如式子9所示,输入中pt(s)中的t表示真实标签类别,s表示scale,因此比如pt(2)表示第二个scale网络的真实标签概率(Figure2中最后预测出来的概率条形图中的绿色部分)。从Lrank损失函数可以看出,当更后面的scale网络的pt大于相邻的前面的scale网络的pt时,损失较小,通俗讲模型的训练目标是希望更后面的scale网络的预测更准。margin参数在实验中设置为0.05。
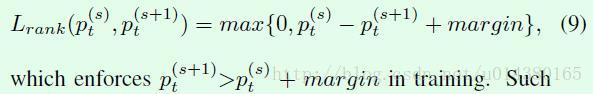
于是这样的网络就可以得到输入X的不同scale特征,比如用式子10表示,其中N表示scale的数量,Fi表示第i个scale网络的全连接层输出,文中称Fi为descriptor。
那么如何融合不同scale网络的输出结果呢?答案如原文所示:To leverage the benefit of feature ensemble,* we first normalize each descriptor independently, and concatenate them together into a fully-connected fusion layer with softmax function for the final classification.*
具体的训练策略如下,非常清楚:
Step 1: we initialize convolutional/classification layers in Figure 2 (b1 to b3 and c1 to c3) by the same pre-trained VGG network from ImageNet.
Step 2: we consider a square (represented by tx, ty, tl) with the half length of the side of original image. The square is selected by searching regions in the original image, with the highest response value in the last convolutional layer (i.e., conv5 4 in VGG-19). We can further obtain a smaller square by analyzing convolutional responses at the second scale in a similar way. These selected squares are used to pre-train APN to obtain parameters in Figure 2 (d1), (d2) by learning the transformation from convolutional feature maps to {tx, ty, tl}.
Step 3: we optimize the parameters in the above two steps in an alternative way. **Specifically, we keep APN parameters unchanged, and optimize the softmax losses at three scales to converge. Then we fix parameters in convolutional/classification layers, and switch to ranking loss to optimize the two APNs. The learning process for the two parts is iterative, until the two types of losses no longer change. **Besides, tl at each scale is constrained to be no less than one-third of the previous tl at coarse scale, to avoid the incompleteness of object structures when tl is too small.
可以看出在step1和step2中涉及不少初始化操作,这些操作有利于模型的快速收敛。step3的交替训练策略比较新颖,有点GAN的意思。
接下来简单介绍APN网络的梯度更新情况,文中有更详细的例子。前面提到的APN网络用于从特征生成区域信息(tx、ty、tl),这3个坐标值通过Mask实现crop操作,这个过程的示意图可以看Figure3。第一行的两个图分别表示两个不同scale网络的输入,第二行表示在训练网络时回传的梯度值分布情况,箭头就是表示梯度的更新方向,比如右下角图中的tx和ty的更新方向是趋于输入图像的右下角区域,tl的更新方向是变得更大。

在conclusion部分,作者也对未来的工作方向做了介绍:First, how to simultaneously preserve global image structure and model local visual cues, to keep improving the performance at finer scales. Second, how to integrate multiple region attention to model more complex fine-grained categories. 可以看出第一点主要针对在实验中scale 3网络的效果不及scale 2网络的效果,主要原因是scale 3丢失了较多的全局信息。第二点是关于如何融合不同scale的region attention信息,毕竟在RA-CNN中不同scale的attention信息之间没有做融合。
实验结果:
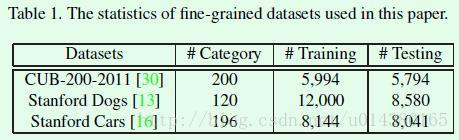
首先是数据集,主要包括Caltech-UCSD Birds (CUB-200-2011), Stanford Dogs 和 Stanford Cars,具体信息如Table1所示:
对比的模型主要分为采用类似bounding box标注的监督式训练和不采用bounding box标注的无监督式训练这两种不同的attention localization算法。输入图像尺寸方面:Input images (at scale 1) and attended regions (at scale 2,3) are resized to 448×448 and 224×224 pixels respectively in training, due to the smaller object size in the coarse scale.
在CUB-200-2011数据集上关于attention localization的效果对比如Table2所示。第三行表示The result of RA-CNN with initialized attended region and without ranking loss optimization. 从第三行的结果可以看出ranking loss的重要性(与第四行对比)。

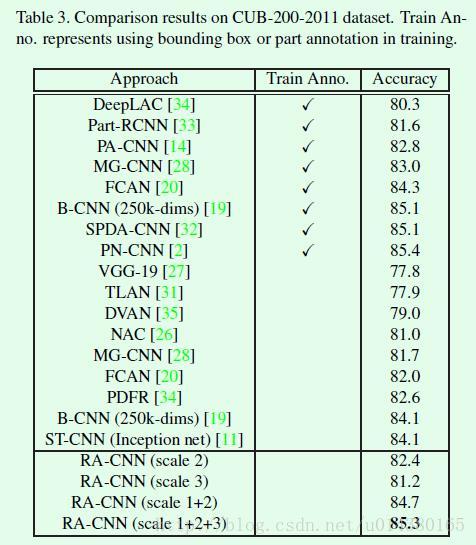
在CUB-200-2011数据集上几个算法的结果对比如Table3所示。第二列的train Anno. 表示在训练过程中是否采用bounding box或part annotation等标注信息进行训练。可以看出RA-CNN的效果基本上和细粒度分类中最优秀的监督式算法的效果差不多。另外和其他非监督式算法相比,RA-CNN的效果则要好很多,即便是B-CNN采用了超高的维度,ST-CNN采用了更好的主网络(Inception)。其他方面,从RA-CNN不同scale的对比可以看出,scale 2的效果要优于scale 1和scale 3,前者是因为关键区域的定位起了效果,后者是因为丢失了部分全局信息。不同scale网络的结果融合可以通过一个全连接层训练参数得到,原文如下:To further leverage the advantages of ensemble learning, features from multiple scales are deeply fused to classify an image by learning a fully-connected fusion layer.
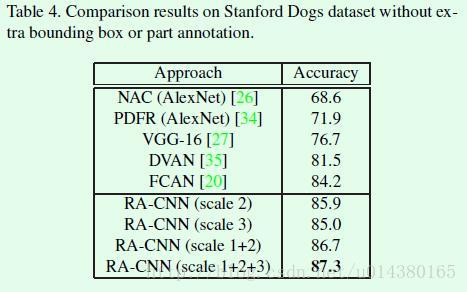
在Stanford Dogs数据集上的对比结果如Table4所示:
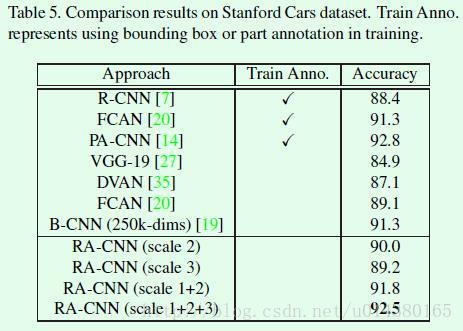
在Stanford Cars数据集上的对比结果如Table5所示:
最后贴一张3个数据集的scale 3网络crop的结果,如Figure5所示:

转载自原文链接, 如需删除请联系管理员。
原文链接:RA-CNN算法笔记,转载请注明来源!