爬虫:爬取全书网,获取数据,存到数据库
工具:mysql,python3
模块:requests(pip install requests),re(不需要安装),pymysql
网址:http://www.quanshuwang.com/

分析网站结构:
查看分类,发现每个分类都有一个id(网址)。观察网址情况,发现规律!只是网址后面的数字不一样,各个网址是与分类的顺序对应的。
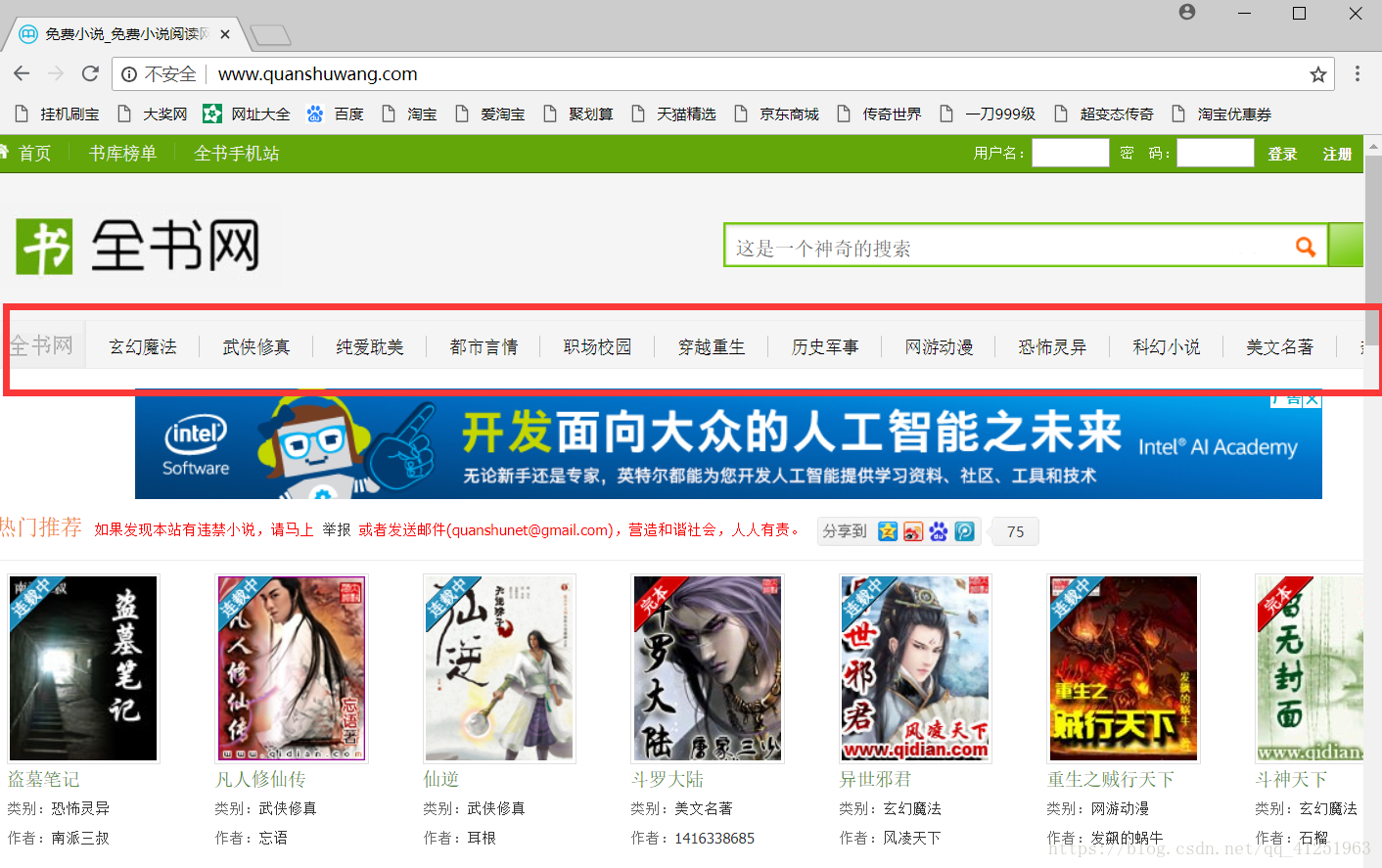
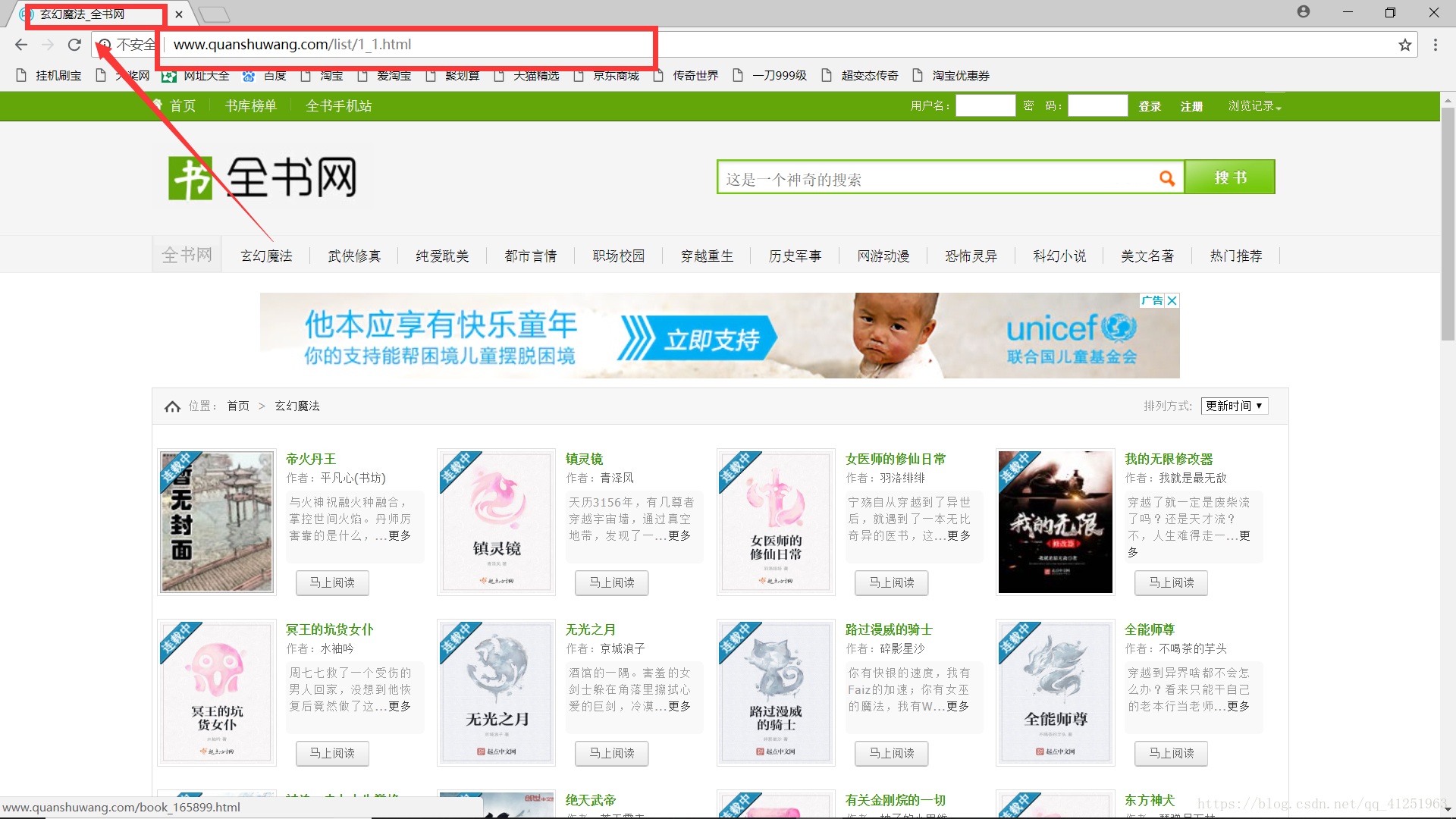
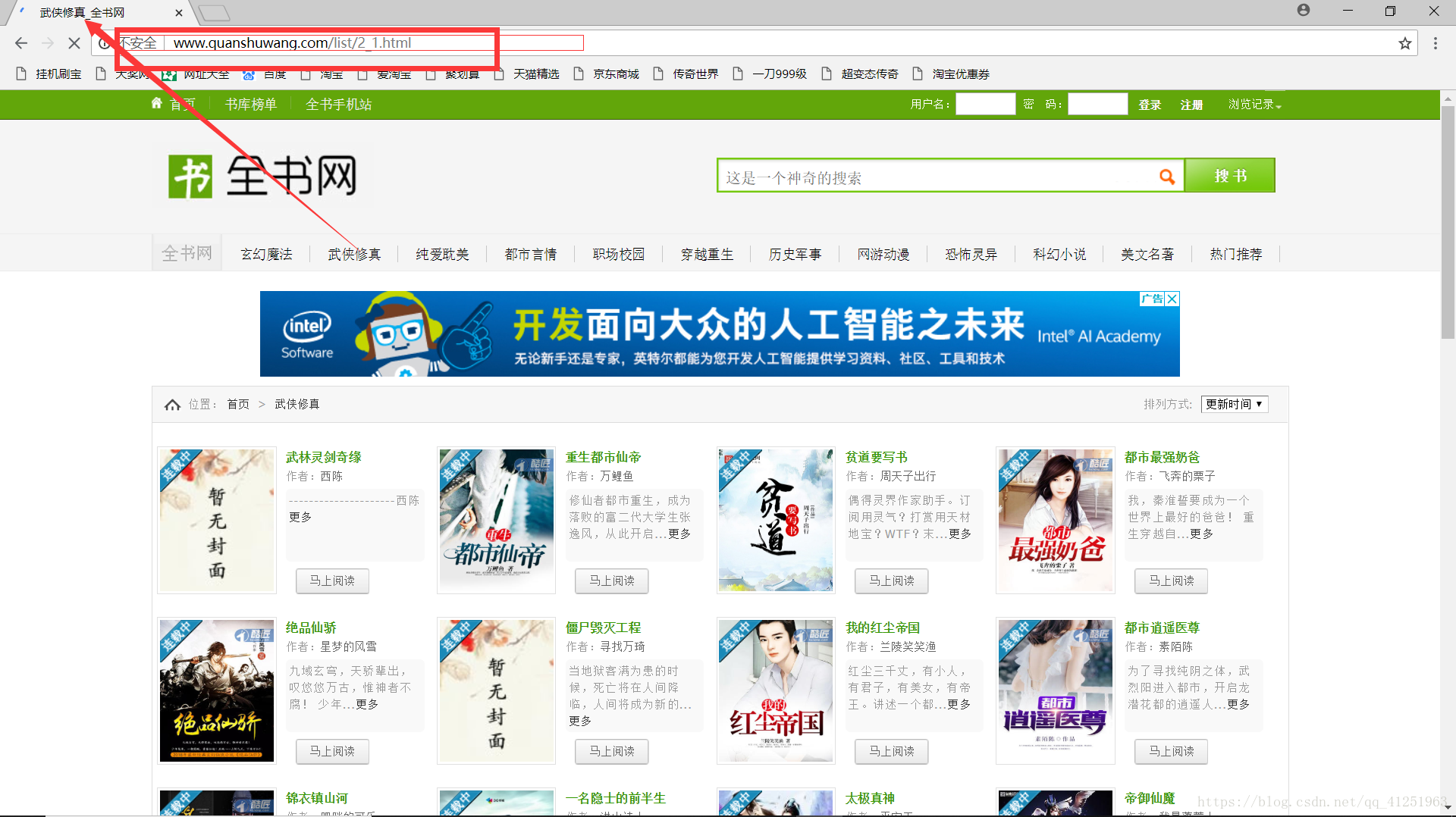
我们可以先创建一个分类的字典:
sort_dict={
'1':'玄幻魔法',
'2':'武侠修真',
'3':'纯爱耽美',
'4':'都是言情',
'5':'职场校园',
'6':'穿越重生',
'7':'历史军事',
'8':'网络动漫',
'9':'恐怖灵异',
'10':'科幻小说',
'11':'美文名著',
}
for sort_id,sort_name in sort_dict.items():
print(sort_id,sort_name)创建一个函数,用于构造每类的网址。访问一下
import requests
sort_dict={
'1':'玄幻魔法',
'2':'武侠修真',
'3':'纯爱耽美',
'4':'都是言情',
'5':'职场校园',
'6':'穿越重生',
'7':'历史军事',
'8':'网络动漫',
'9':'恐怖灵异',
'10':'科幻小说',
'11':'美文名著',
}
def getList(sort_id,sort_name):
html = requests.get("http://www.quanshuwang.com/list/%s_1.html"%sort_id)
print(html.text)
for sort_id,sort_name in sort_dict.items():
getList(sort_id,sort_name)
break
执行程序,发现乱码现象。我们看一下原网页的代码是什么?
原网页编码是gbk
在代码中指定一下。添加html.encoding=’gbk’
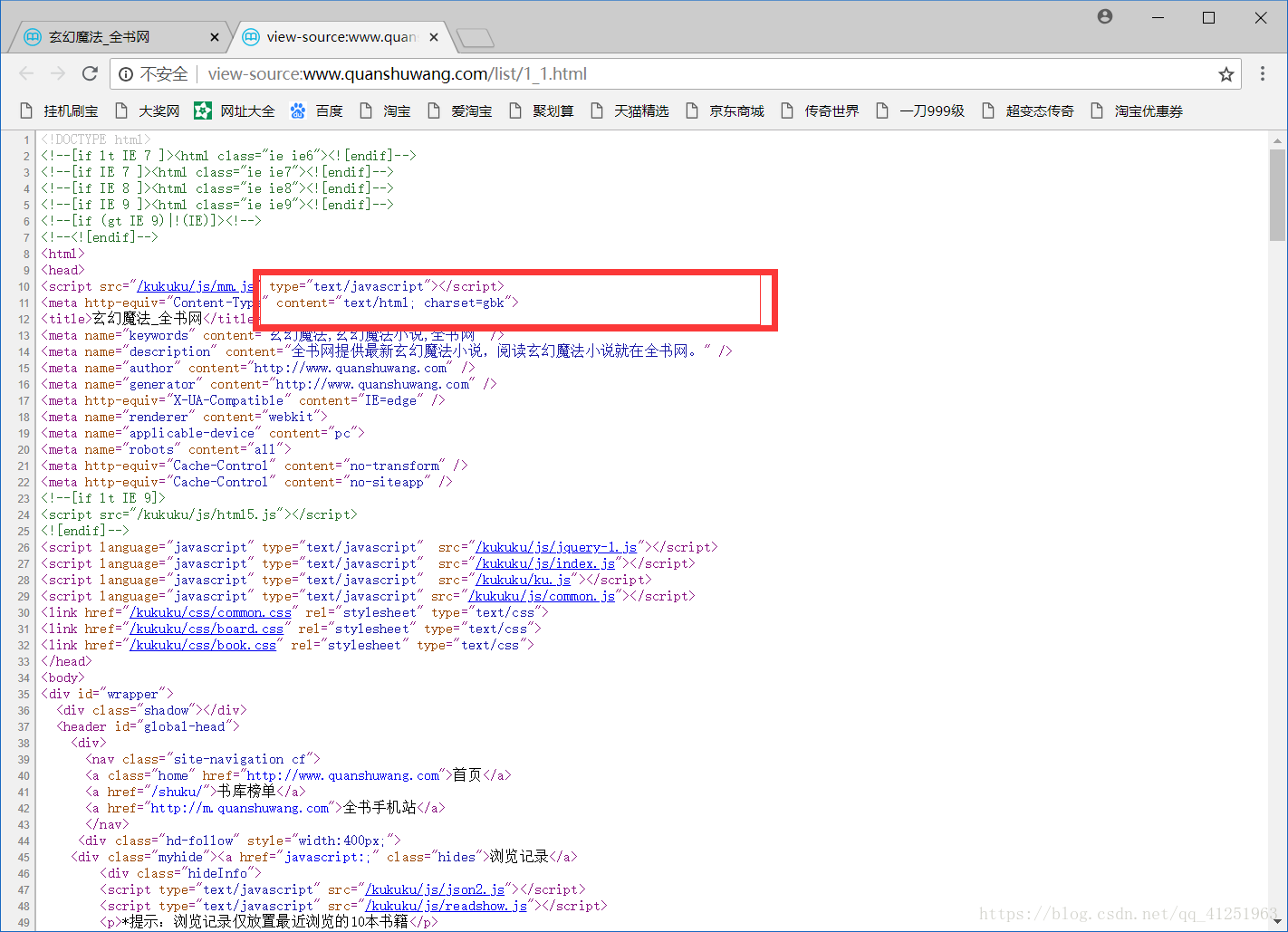
def getList(sort_id,sort_name):
html = requests.get("http://www.quanshuwang.com/list/%s_1.html"%sort_id)
html.encoding='gbk'
print(html.text)
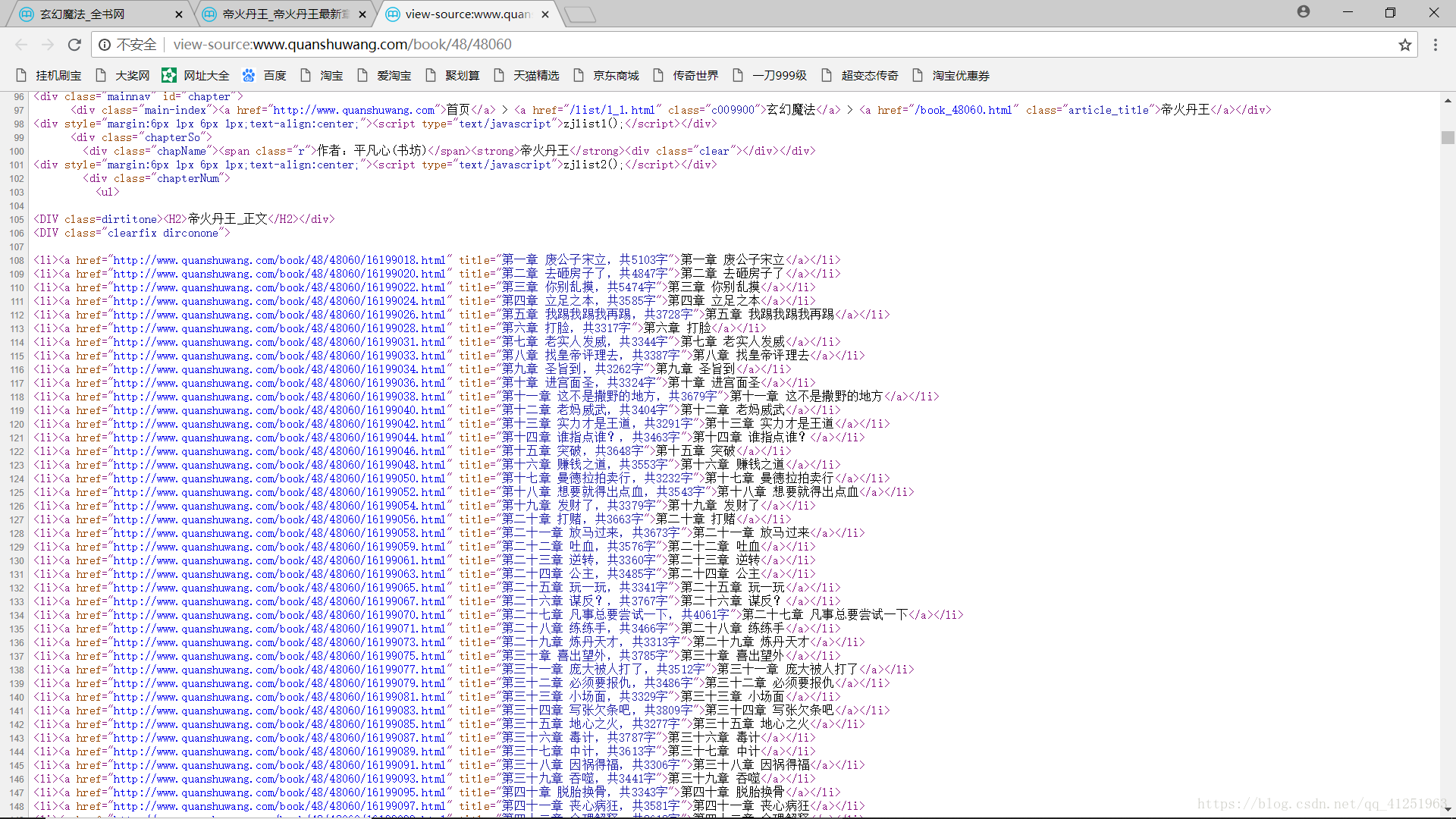
利用正则表达式获取当前分类页面下的所有小说网址;
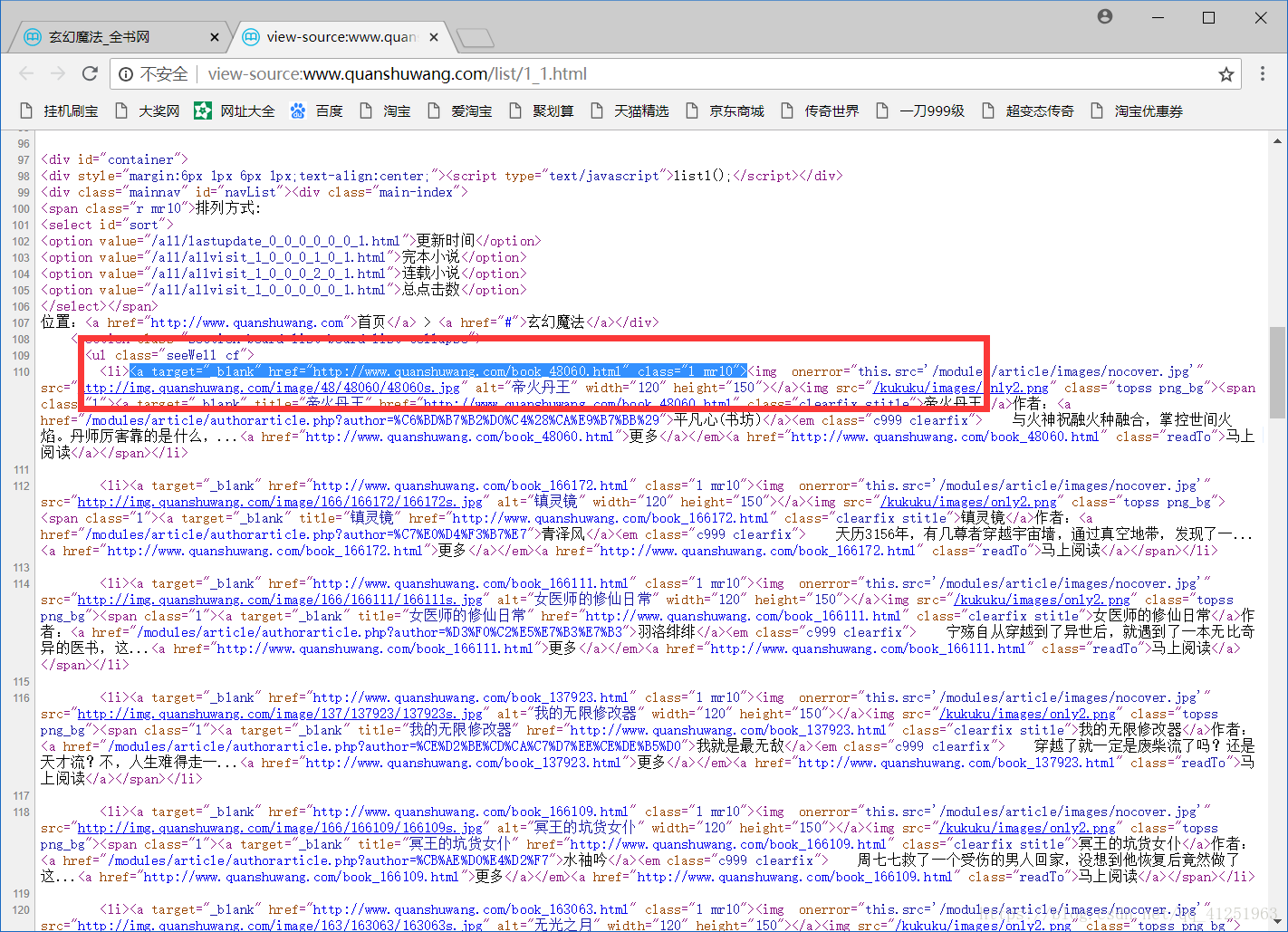
reg = r'<a target="_blank" href="(.*?)" class="l mr10">'
urlList=re.findall(reg,html.text)再创建一个函数,用来访问小说的页面。参数url是上面用正则表达式匹配出来urlList列表中的网址。
def getNovel(url):
html=requests.get(url)
html.encoding='gbk'
print(html.text)也就是这个页面
我们查看一下这个页面的网页源代码
红色标记部分,有书的图片,书的名称,描述,分类,及作者等信息。
接下来,我们就把这些信息提取出来。(利用正则表达式,用(.*?)提取信息)
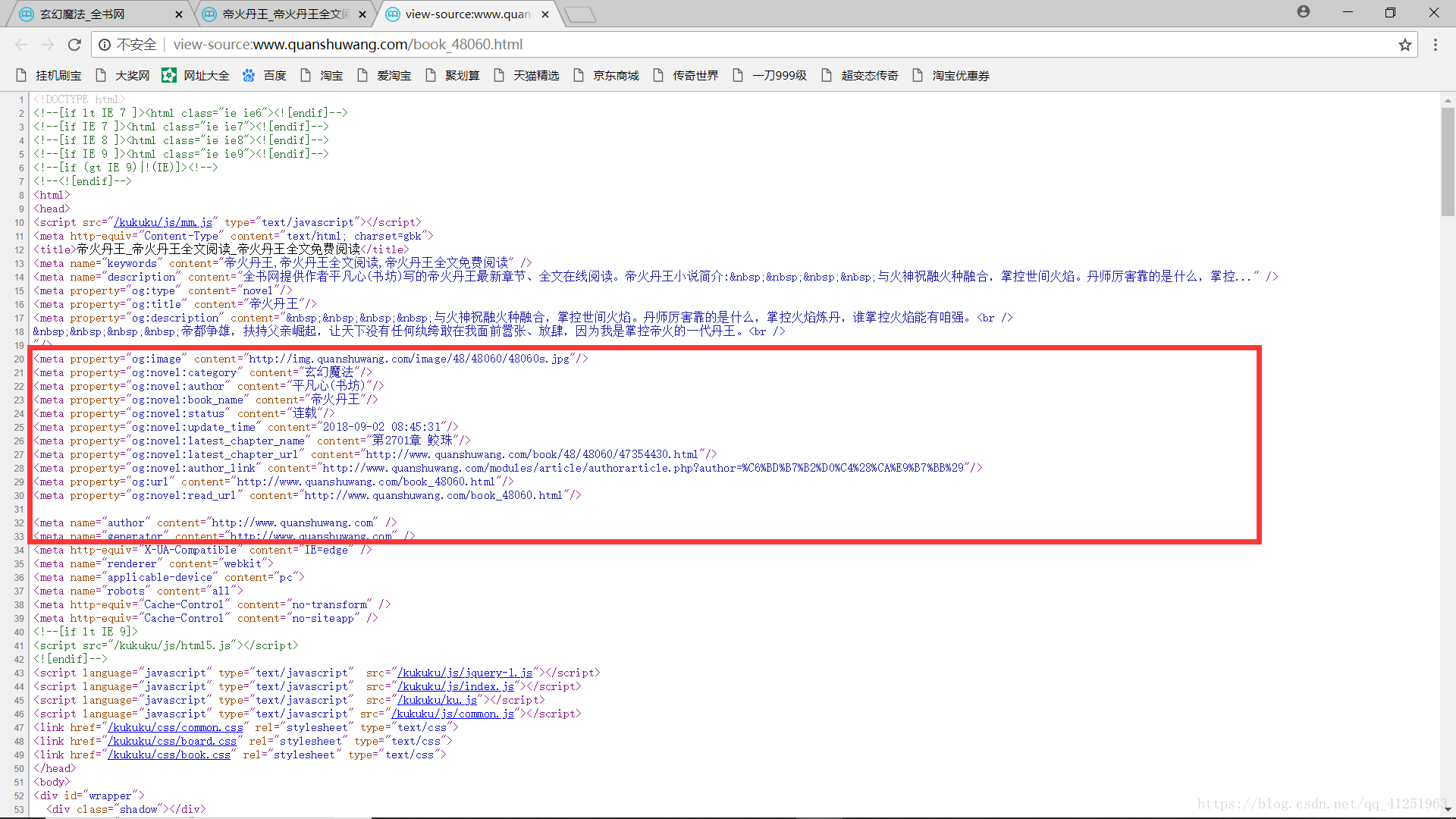
#获取书名
reg=r'<meta property="og:novel:book_name" content="(.*?)"/>'
bookname=re.findall(reg,html.text)[0]
#获取描述
reg = r'<meta property="og:description" content="(.*?)"/>'
description=re.findall(reg,html.text,re.S)[0]#re.S支持换行符
#获取图片
reg = r'<meta property="og:image" content="(.*?)"/>'
image=re.findall(reg,html.text)[0]
#获取作者
reg=r'<meta property="og:novel:author" content="(.*?)"/>'
author=re.findall(reg,html.text)[0]
#获取状态
reg=r'<meta property="og:novel:status" content="(.*?)"/>'
status=re.findall(reg,html.text)[0]
#获取章节地址
reg=r'<a href="http:(.*?)" class="reader"'
chapterUrl=re.findall(reg,html.text)[0]
拿到章节地址,我们想要获取章节
同样使用正则表达式:
reg=r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>'
chapterInfo=re.findall(reg,html.text)
获取章节的网址及标题,访问章节网址,再次使用正则表达式匹配章节内容。
这样就能把小说的所有信息都能获取到了。具体操作参照源代码。
完整代码
import requests
import re
import pymysql
class Sql(object):
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='mysql',
db='novel',
charset='utf8')
def addnovel(self,sort,sortname,name,imgurl,description,status,author):
cur=self.conn.cursor()
cur.execute("insert into novel(sort,sortname,name,imgurl,description,status,author) values('%s','%s','%s','%s','%s','%s','%s') "\
%(sort,sortname,name,imgurl,description,status,author))
lastrowid=cur.lastrowid
cur.close()#关闭游标
self.conn.commit()
return lastrowid
def addchapter(self,novelid,title,content):
cur=self.conn.cursor()
cur.execute("insert into chapter(novelid,title,content) values('%s','%s','%s')"%(novelid,title,content))
cur.close()
self.conn.commit()
mysql=Sql()#实例对象
sort_dict={
'1':'玄幻魔法',
'2':'武侠修真',
'3':'纯爱耽美',
'4':'都是言情',
'5':'职场校园',
'6':'穿越重生',
'7':'历史军事',
'8':'网络动漫',
'9':'恐怖灵异',
'10':'科幻小说',
'11':'美文名著',
}
def getChapterContent(url,lastrowid,title):
html=requests.get(url)
html.encoding='gbk'
#print(html.text)
reg=r'style5\(\);</script>(.*?)<script type="text/javascript">style6\(\);</script></div>'
html=re.findall(reg,html.text,re.S)[0]
mysql.addchapter(lastrowid,title,html)
def getChapterList(url,lastroeid):
html=requests.get(url)
html.encoding='gbk'
reg=r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>'
chapterInfo=re.findall(reg,html.text)
for url,title in chapterInfo:
#print(url)
getChapterContent(url,lastroeid,title)
def getNovel(url,sort_id,sort_name):
html=requests.get(url)
html.encoding='gbk'
#获取书名
reg=r'<meta property="og:novel:book_name" content="(.*?)"/>'
bookname=re.findall(reg,html.text)[0]
#获取描述
reg = r'<meta property="og:description" content="(.*?)"/>'
description=re.findall(reg,html.text,re.S)[0]#re.S支持换行符
#获取图片
reg = r'<meta property="og:image" content="(.*?)"/>'
image=re.findall(reg,html.text)[0]
#获取作者
reg=r'<meta property="og:novel:author" content="(.*?)"/>'
author=re.findall(reg,html.text)[0]
#获取状态
reg=r'<meta property="og:novel:status" content="(.*?)"/>'
status=re.findall(reg,html.text)[0]
#获取章节地址
reg=r'<a href="(.*?)" class="reader"'
chapterUrl=re.findall(reg,html.text)[0]
print(bookname,author,image,status,chapterUrl)
#插入数据
lastrowid=mysql.addnovel(sort_id,sort_name,bookname,image,description,status,author)
getChapterList(chapterUrl,lastrowid)
def getList(sort_id,sort_name):
html = requests.get("http://www.quanshuwang.com/list/%s_1.html"%sort_id)
html.encoding='gbk'
#print(html.text)
reg = r'<a target="_blank" href="(.*?)" class="l mr10">'
urlList=re.findall(reg,html.text)
#print(urlList)
for url in urlList:
getNovel(url,sort_id,sort_name)
for sort_id,sort_name in sort_dict.items():
getList(sort_id,sort_name)
数据库建表:
建立数据库名为novel
在novel数据库中建立两个表,chapter用于存储章节内容,novel用于存储小说的一些信息
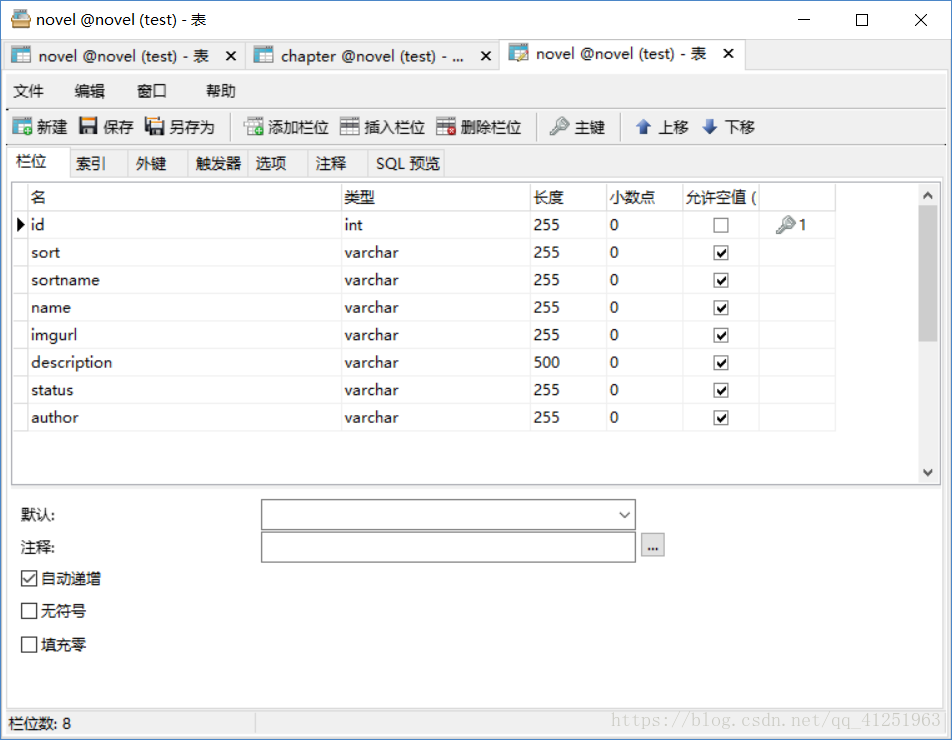
设计表:
novel
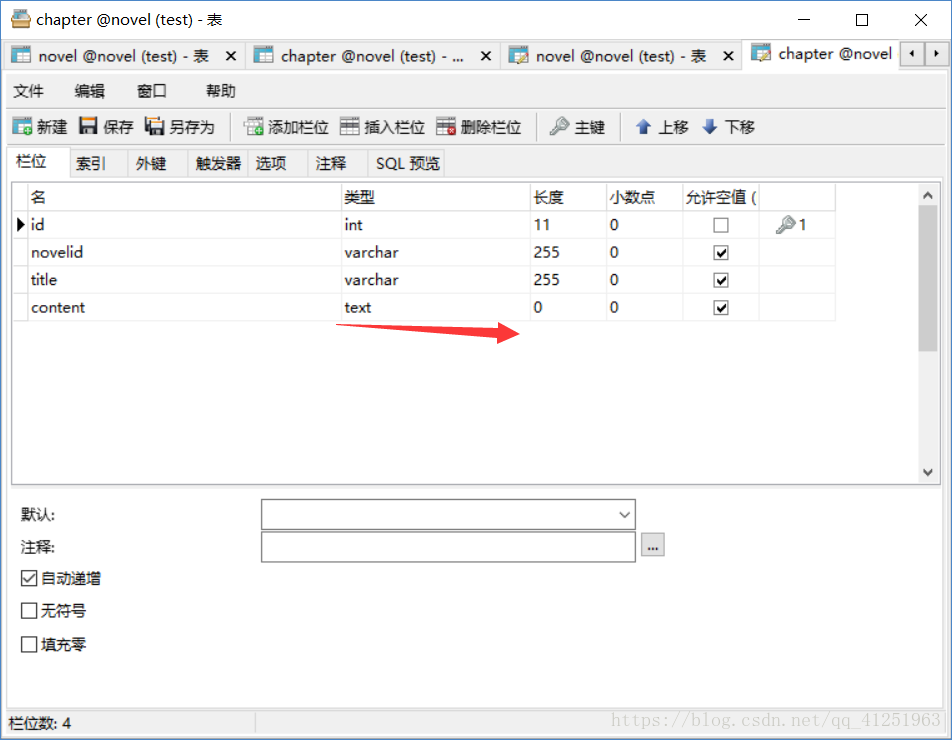
chapter
以上就是获取全书网的所有小说过程,当然这样写代码,爬取的过程会很慢,可以修改代码利用多线程爬取。
使用上述代码,仅需要将数据库连接部分改为你自己的数据库信息。
需要更改部分:

希望批评改正!可在下方留言
转载自原文链接, 如需删除请联系管理员。
原文链接:python爬虫——全书网,转载请注明来源!