目录
awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,默认以空格为分隔符将每行切片,切开的部分再进行各种分析处理。 awk是行处理器,相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程: 依次对每一行进行处理,然后输出
awk的用法:
awk 参数 ' BEGIN{} // {action1;action2} ' END{} 文件名
参数:
- -F 指定分隔符
- -f 调用脚本
- -v 定义变量
Begin{} 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令,多条命令用 ; 隔开
END{} 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
例: awk 'BEGIN{X=0}/root/{X+=1}END{print "I find",X,"root lines"}' /etc/passwd 统计 /etc/passwd 文件中包含root行的总数


awk中字符的含义:
- $0 表示整个当前行
- $1 每行第一个字段
- NF 字段数量变量
- NR 每行的记录号,多文件记录递增
- FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
- \t 制表符
- \n 换行符
- FS BEGIN时定义分隔符
- RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
- ~ 包含
- !~ 不包含
- == 等于,必须全部相等,精确比较
- != 不等于,精确比较
- && 逻辑与
- || 逻辑或
- + 匹配时表示1个或1个以上
- /[0-9][0-9]+/ 两个或两个以上数字
- /[0-9][0-9]*/ 一个或一个以上数字
- OFS 输出字段分隔符, 默认也是空格,可以改为其他的
- ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
- -F [:#/] 定义了三个分隔符
print 打印
- print 是 awk打印指定内容的主要命令,也可以用 printf
- awk '{print}' /etc/passwd == awk '{print $0}' /etc/passwd
- awk '{print " "}' /etc/passwd 不输出passwd的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本
- awk '{print "a"}' /etc/passwd 输出相同个数的a行,一行只有一个a字母
- awk -F: '{print $1}' /etc/passwd == awk -F ":" '{print $1}' /etc/passwd
- awk -F: '{print $1 $2}' 输入字段1,2,中间不分隔
- awk -F: '{print $1,$3,$6}' OFS="\t" /etc/passwd 输出字段1,3,6, 以制表符作为分隔符
- awk -F: '{print $1; print $2}' /etc/passwd 输入字段1,2,分行输出
- awk -F: '{print $1 "**" print $2}' /etc/passwd 输入字段1,2,中间以**分隔
- awk -F: '{print "name:"$1"\tid:"$3}' /etc/passwd 自定义格式输出字段1,2
- awk -F: '{print NF}' /etc/passwd 显示每行有多少字段
- awk -F: 'NF>2{print }' /etc/passwd 将每行字段数大于2的打印出来
- awk -F: 'NR==5{print}' /etc/passwd 打印出/etc/passwd文件中的第5行
- awk -F: 'NR==5|NR==6{print}' /etc/passwd 打印出/etc/passwd文件中的第5行和第6行
- awk -F: 'NR!=1{print}' /etc/passwd 不显示第一行
- awk -F: '{print > "1.txt"}' /etc/passwd 输出到文件中
- awk -F: '{print}' /etc/passwd > 2.txt 使用重定向输出到文件中
字符匹配
- awk -F: '/root/{print }' /etc/passwd 打印出文件中含有root的行
- awk -F: '/'$A'/{print }' /etc/passwd 打印出文件中含有变量 $A的行
- awk -F: '!/root/{print}' /etc/passwd 打印出文件中不含有root的行
- awk -F: '/root|tom/{print}' /etc/passwd 打印出文件中含有root或者tom的行
- awk -F: '/mail/,mysql/{print}' test 打印出文件中含有 mail*mysql 的行,*代表有0个或任意多个字符
- awk -F: '/^[2][7][7]*/{print}' test 打印出文件中以27开头的行,如27,277,27gff 等等
- awk -F: '$1~/root/{print}' /etc/passwd 打印出文件中第一个字段是root的行
- awk -F: '($1=="root"){print}' /etc/passwd 打印出文件中第一个字段是root的行,与上面的等效
- awk -F: '$1!~/root/{print}' /etc/passwd 打印出文件中第一个字段不是root的行
- awk -F: '($1!="root"){print}' /etc/passwd 打印出文件中第一个字段不是root的行,与上面的等效
- awk -F: '$1~/root|ftp/{print}' /etc/passwd 打印出文件中第一个字段是root或ftp的行
- awk -F: '($1=="root"||$1=="ftp"){print}' /etc/passwd 打印出文件中第一个字段是root或ftp的行,与上面的等效
- awk -F: '$1!~/root|ftp/{print}' /etc/passwd 打印出文件中第一个字段不是root或不是ftp的行
- awk -F: '($1!="root"||$1!="ftp"){print}' /etc/passwd 打印出文件中第一个字段不是root或不是ftp的行,与上面等效
- awk -F: '{if($1~/mail/) {print $1} else {print $2}}' /etc/passwd 如果第一个字段是mail,则打印第一个字段,否则打印第2个字段
格式化输出
awk '{printf "%-5s %.2d",$1,$2}' test
- printf 表示格式输出
- %格式化输出分隔符
- -8表示长度为8个字符
- s表示字符串类型,d表示小数
举例:
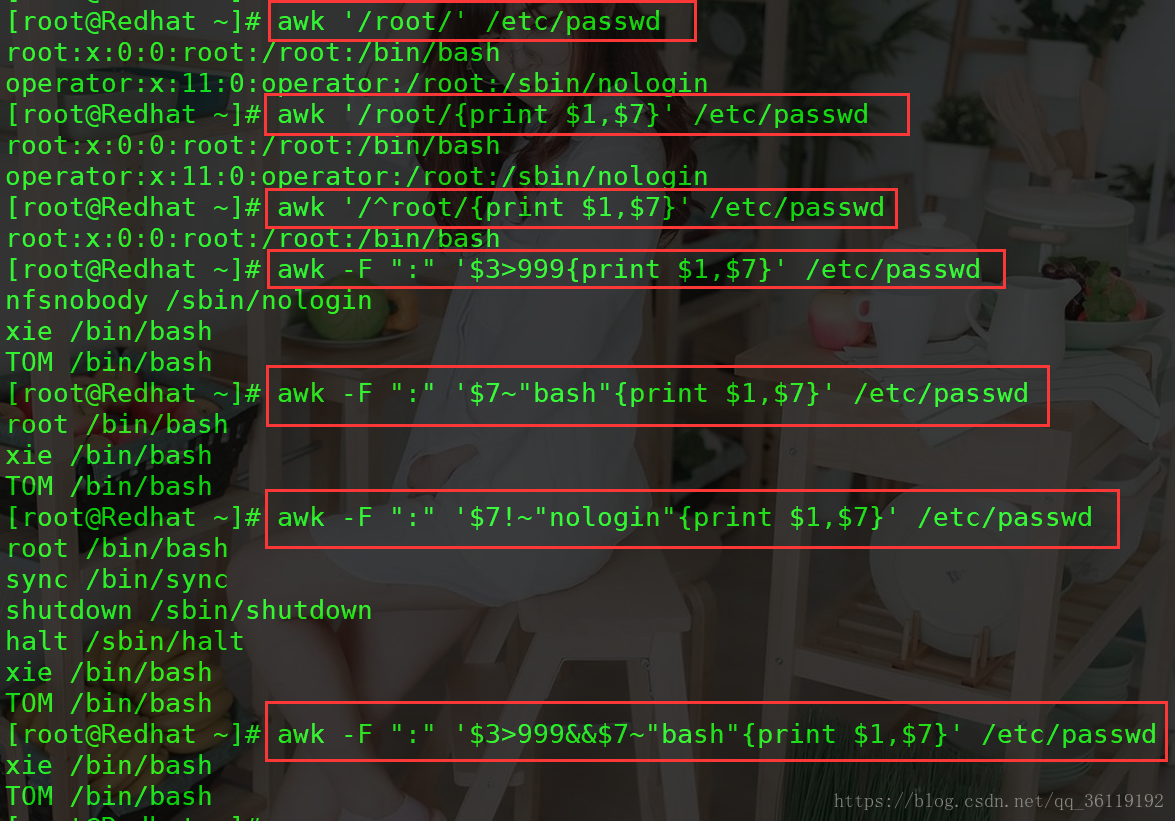
1、显示 /etc/passwd 中含有 root 的行
awk '/root/' /etc/passwd
2、以 : 为分隔,显示/etc/passwd中每行的第1和第7个字段
awk -F ":" '{print $1,$7}' /etc/passwd 或 awk 'BEGIN{FS=":"}{print $1,$7}' /etc/passwd
3、以 : 为分隔,显示/etc/passwd中含有 root 的行的第1和第7个字段
awk -F ":" '/root/{print $1,$7}' /etc/passwd
4、以 : 为分隔,显示/etc/passwd中以 root 开头行的第1和第7个字段
awk -F ":" '/^root/{print $1,$7}' /etc/passwd
5、以 : 为分隔,显示/etc/passwd中第3个字段大于999的行的第1和第7个字段
awk -F ":" '$3>999{print $1,$7}' /etc/passwd
6、以 : 为分隔,显示/etc/passwd中第7个字段包含bash的行的第1和第7个字段
awk -F ":" '$7~"bash"{print $1,$7}' /etc/passwd
7、以 : 为分隔,显示/etc/passwd中第7个字段不包含bash的行的第1和第7个字段
awk -F ":" '$7!~"nologin"{print $1,$7}' /etc/passwd
8、以 : 为分隔,显示$3>999并且第7个字段包含bash的行的第1和第7个字段
awk -F ":" '$3>999&&$7~"bash"{print $1,$7}' /etc/passwd
9、以 : 为分隔,显示$3>999或第7个字段包含bash的行的第1和第7个字段
awk -F ":" '$3>999||$7~"bash"{print $1,$7}' /etc/passwd
转载自原文链接, 如需删除请联系管理员。
原文链接:Linux中awk工具的使用,转载请注明来源!