此篇为我在学习检索时遇到的基础知识的总结,以便巩固复习。
一、信息检索评价指标
最基本指标:查全率R(召回率 Recall rate)、查准率P(Precision rate),计算公式如下:


准确率和召回率是互相影响的,一般情况下查准率高、召回率就低,召回率低、查准率高。在检索中往往要在保证召回率的前提下提高查准率。在对查准率和召回率都要求高时,可以用F-Measure综合考虑他们,当a=1时,就是常见的F1了,F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。计算公式如下:
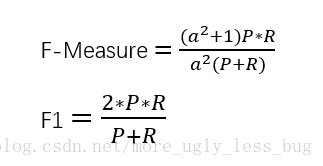
1.1、MAP
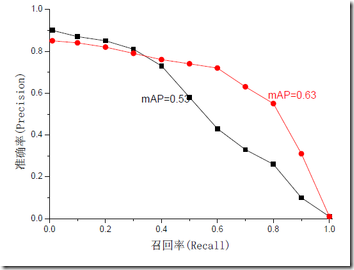
无论是召回率R、查准率P还是F1,都存在有单点值局限性,为了得到 一个能够反映全局性能的指标,引入MAP(mean average precision)。对于P和R,用不同的阀值,可以统计出一组不同阀值下的精确率和召回率,叫做P-R图,如下图所示,两条曲线分布对应了两个检索系统的P-R曲线。虽然两个系统的性能曲线有所交叠。但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。所以P-R曲线更向上突出的系统性能更好,也就是说,P-R曲线与坐标轴之间的面积应当越大越好。MAP即为求P-R曲线与坐标轴包围的面积,理想情况下面积为1。
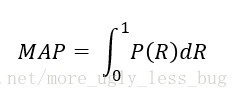
关于上述对MAP的解释,博主仔细翻看了周志华老师的《机器学习》,虽然我对P-R曲线面积的作用描述是没问题的,但是并未发现书中对P-R曲线的面积有过称为MAP的情况。而博主在论文中看到的MAP的使用,应该属于我下一种的解释。两者之间有无关系,我会继续关注。
MAP是评估检索策略效果的方式之一,除了考虑召回结果的整体准确率之外,MAP也考量召回结果条目的顺序。在了解MAP之前,我们要先了解Prec@K和AP@K的概念。
Prec@K表示设定一个阈值K,在检索结果到第K个正确召回为止,排序结果的相关度。假设某次的检索结果如下:

在这个案例中Prec@1=1、Prec@2=2/3、Prec@3=3/5。但是,Prec@K也只能表示单点的策略效果,我们需要使用AP@K体现策略的整体效果。
Average Precision@K是指到第K个正确的召回为止,从第一个正确召回到第K个正确召回的平均正确率。下图为两种K=6的排序策略的结果。
根据经验,我们容易判断出第一种排序好于第二种。对于结果1,AP=(1.0+0.67+0.75+0.8+0.83+0.6)/6=0.78,对于结果2,AP=(0.5+0.4+0.5+0.57+0.56+0.6)/6=0.52,可以看到,效果优的策略1的AP@K值大于效果劣的策略2。

对于一次查询,AP值可以判断优劣,但是如果涉及到一个策略在多次查询的效果,我们需要引入另一个概念MAP(Mean Average Precision),简单的说,MAP的计算的是搜索查询结果AP值的均值。如上图如果表示的是一个策略下,两次不同的搜索的结果,则MAP = (0.78+0.52)/2。
评价查询和文档的相关度传统上使用两种特征,一种是和词项Term相关的特征,例如BM25。另一种是独立于Term的特征,例如PageRank。
1.2、TF-IDF
转载自原文链接, 如需删除请联系管理员。
原文链接:信息检索基础知识总结,转载请注明来源!