在《机器学习基石》这门课里面也进入了第一讲的内容,这次学习到的是Percetron Learning Algorithm——感知学习算法。
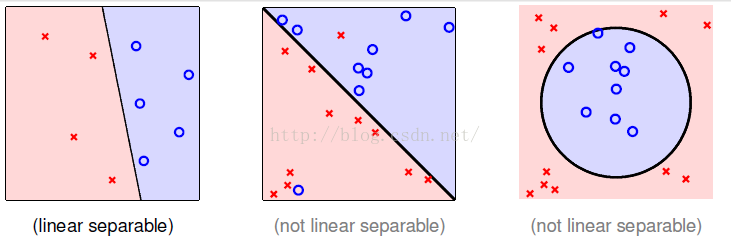
PLA用于解决的是对于二维或者高维的 线性可分 问题的分类,最终将问题分为两类——是或者不是。
注意PLA一定是针对线性可分的问题,即可以找到一条线,或者超平面去分开是和不是的两堆数据,如果不是线性可分。
可以通过后来的Pocket改正算法,类似贪心的法则找到一个最适合的。

一个很好的用于PLA的例子是银行要不要给用户发信用卡的问题。银行可以根据顾客的个人信息来判断是否给顾客发放信用卡。将顾客抽象为一个向量X,包括姓名、年龄、年收入、负债数等。同时设定各个属性所占的比例向量W,对于正相关的属性设置相对较高的比例如年收入,对于负相关的属性设置较低的比例如负债数。y表示是否想该用户发放了信用卡。通过求X和W的内积减去一个阀值,若为正则同意发放信用卡,否则不发放信用卡。我们假设存在着一个从X到Y的映射f,PLA算法就是用来模拟这个映射,使得求出的函数与f尽可能的相似,起码在已知的数据集上一致。
PLA算法即用来求向量W(用于预测的向量),使得在已知的数据中机器做出的判断与现实完全相同。当X为二维向量时,相当于在平面上画出一条直线将所有的点分成两部分,一部分同意发送,另外的不同意。内积可以表示成:
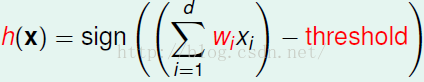
如果把(阈值*-1)当作Wo,x0当作1,公式可以化简为
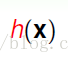

这里面WT 就是用来做预测的向量,h(x)是假定求出来的预测函数,算法的关键就是去求w。
算法的思路可以简单这样理解,x相当于给定的已知值,wT 可能会把x带到正的那一边,也可能把x带到负的那一边。然而,最后可能正确的值是正的,却带到了负的。
正确是负的,却带到了正的。那么根据所给的训练集,可以不断的去修正这个Wt,以满足训练集的数据情况。
例如:
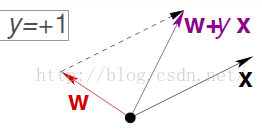
x的指向代表了y的布尔值。
上图的例子可以看到,如果x的实际指向是如果是正的,即y = +1,然而w的预测值却与x的夹角大于90,即预测到反方向 wT* x= -1。结果不正确。
那么可以通过y*x的纠正值来纠正w,这样新的w又会和x处于一个方向上了。两者点乘得出的值就是负的。
另外一种情况:
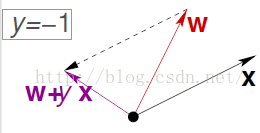
x的值指向负的,,y = -1。然而w 与 x 的夹角小于 90度,那么通过预测,wT* x= 1,结果也不正确。
同理可以加上一个y*x,来修正w。这样wT * x 又可以变成 -1了。
算法的思路就大概是这样:
initialize w(0) = 0.
for t = 0,1,2,....
for i = 1,2,...,n
w(t+1) = w(t) + y(i) * x(i);
end
直到所有的点都预测正确为止。
(线性可分的数据可以通过证明得出,这个循环最后一定会停下来,不会无限循环)
end算法证明(即线性可分可以得到终止):
这里我直接引用别人的算式结果了,计算过程写得比较清楚。

可以看到,运行次数T是存在上界的。意思就是如果给定的资料是线性可分,那么最后一定可以得到一个w,分开两个数据集。
PLA的优缺点:
1.首先,PLA的算法是局限在线性可分的训练集上的,然而我们拿到一个训练集,并不知道其到底是不是线性可分,如果不是,PLA的算法程序将无限循环下去,这样做是不可 行的。
2.即使训练集是线性可分,我们也不知道PLA什么时候才能找到一个合适的解,如果要循环很多次才能找到,这对于实际使用是开销很大的。
PLA改进——Pocket Algorithm:
针对不是线性可分的数据,这里提出了一个改进的算法。
思路是,能否找到一条分界线去分离两个数据集,使得错误率最低呢?
然而要准确找到一条错误率最低的,被证明出是一个NP问题,不能准确地找到。那么Pocket算法的思路就是,类似贪心,如果找到一个更好(错误率低)的w,那么就去更新,
如果找一个错误率更高的,那么就不去更新的,重新找。每次找一个随机的wt。对于所有数据都采用w(t+1) = w(t) + yn * xn; 修正一次。最后如果这个wt要比记录的最好值w‘犯的错误少,就更新最好值。
下面是伪代码:
for t = 1,2,3... (number of iteration)
w(t) = random of w ;
for i = 1,2,3...n
w(t+1) = w(t) + y(i) * x(i);
end
if(cal_error(w(t+1)) < cal_error(w_best)))
w_best = w(t+1);
end 同理,Pocket算法也有它自己的缺点:
1.wt是随机的,可能算了很多次都没有找出一个更好的。
2.假设数据一开始就是线性可分,那么这个算法找出来的未必是最好解,且时间花费也可能比较大。
总结:
这次是第一次学习机器学习的内容,PLA的算法局限性比较大,一定要针对线性可分的数据,且只能用来做二元分类,如果是多元分类,恐怕还要进一步学习其他算法。
Pocket算法可以解决PLA线性可分的未知性,但是自身缺点也比较大,如果设定的迭代字数太少,可能找到的解不够好,太多又可能给计算带来太大开销。
转载自原文链接, 如需删除请联系管理员。
原文链接:PLA算法总结——Percetron Learning Algorithm(机器学习基石2),转载请注明来源!