http://blog.csdn.net/xiaojimanman/article/details/43052829
前面我们介绍了Analyzer和Query,这篇我们就开始该系列最后一个类IndexSearcher的搜索API介绍,Lucene中重点API不止这里介绍的这一点,还有IndexWriter、Field、Highlighter等,这些就不在这一部分做介绍了,如若案例中用到的话,再做简单介绍。
查看Lucene4.3.1中IndexSearcher的API请
点击这里,关于搜索的方法如下图:

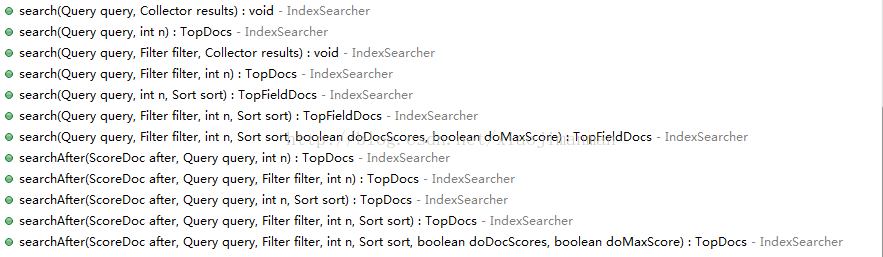
从上图几个方法可以看出,有几个重点类需要介绍下:Query(上篇博客已介绍)、Filter、Sort、ScoreDoc、Collector
Collector
Collector主要用来对搜索结果做收集、自定义排序、过滤等,在Lucene4.3.1的API中,有两个搜索方法用到了Collector,但是其下面都有一句Lower-level search API(低级别的搜索API),如果没有非用不可的需求,尽量还是使用其他方法。
Filter
Filter主要是做筛选条件的,用于指定哪些文档可以在搜索结果中,这个自己使用的并不是太多,查询了一些资料,介绍说有Filter的检索过程是先对数据源做筛选预处理(Filter中指定的),然后将筛选的结果交给查询语句,如果是这样的话,使用Filter的代价将会很大,他的查询耗时可能会提高数倍。个人认为也没有必要使用Filter,如果真的需要对结果做筛选,可以把这些筛选条件合并到Query中,而没有必要创建一个Filter对象。
Sort
Sort在检索方法中指定排序方式,相当于数据库中的order by,创建方式如Sort sort = new Sort(new SortField("time", Type.LONG, true)),这里的SortField构造方法中的三个参数分别代表域名、域数据类型、排序方式(true降序/false升序),这里的例子只是按照一个域进行排序,如果多个域可以直接在构造方法中添加,如sort = new Sort(new SortField("time", Type.LONG, true), new SortField("star", Type.INT, false))。
ScoreDoc
从上图方法中,searchAfter方法中使用到ScoreDoc,该方法主要用在分页查询中,当然也可以用search方法替代,但是有一种情况是无法替代的,比如查询第一页10条数据,但由于推广或广告等需求,需要在其中添加几条(具体未知)其他记录,但是前端只能展示10条数据,这样该页的最后几条数据就没有办法显示,但在下一页中又想显示这几条数据,这样使用seach方法实现就有点困难,事例需求图形描述如下:

searchAfter在实现上述的需求时,在取下一页数据时,只需要将上次查询的最后一个ScoreDoc告诉它即可,它可以直接从该条数据开始查询下一页的数据。
检索方法中涉及到的类也算介绍结束了,现在就将这些组装起来,以最简单的一个检索方法为例search(Query query, int n),该方法实现的是检索符合条件query的前N条文档,这里的排序采用的是默认的相关度排序;这样方法中添加其他的对象,就完成了其对应的功能,如search(Query query, int n, Sort sort),该方法指定了其排序方式。这篇博客主要介绍IndexSearcher的搜索相关API,所以这里就不再写测试demo了。
IndexWriter
原计划第一部分到现在应该结束的,也不对其他内容做相关介绍的,但读者的反馈说索引的增删改的方法不是太清楚,那这里就先简单的题以下其方法,自己感兴趣的可以先实现下,添加新文档到索引中这个在
创建索引这篇博客中已经提到,这里就不再介绍。
修改索引
public boolean updateDocument(Term term, Document doc){
try {
indexWriter.updateDocument(term, doc);
return true;
} catch (IOException e) {
e.printStackTrace();
return false;
}
} 这里的term指定了要修改的索引文档,一般这里使用索引中文档的唯一标识。
删除索引
public boolean deleteDocument(Query query){
try {
indexWriter.deleteDocuments(query);
return true;
} catch (IOException e) {
e.printStackTrace();
return false;
}
} 这里的query指定了文档需要满足的条件,当然也有方法可以直接清空索引
public boolean deleteAll(){
try {
indexWriter.deleteAll();
return true;
} catch (IOException e) {
e.printStackTrace();
return false;
}
}上述的这些操作,都需要执行indexWriter.commit()之后才会保存,否则是不会有效的。
注:第一部分:lucene的基本原理以及API简单接口的使用 到这里就结束了,按照数据流向下一部分应该介绍数据采集的,但为了在介绍搜索后台部分不忘记lucene的相关知识,这里就把搜索后台部分稍微提前一点。在开始搜索后台部分之前,我也会在1-2篇博客中,介绍一下这个案例的demo以及后台的系统架构,在对整个需求有一定的了解基础之上,我们再开始案例开发。如若对个人的博客在排版或者内容等方面有相关的意见,真心希望在评论中可以提及,我也会积极采纳各位的建议,把这一个系列的博客做好,大家共同进步。
ps:最近发现其他网站可能会对博客转载,上面并没有源链接,如想查看更多关于
基于lucene的案例开发 请
点击这里。或访问网址http://blog.csdn.net/xiaojimanman/article/category/2841877
转载自原文链接, 如需删除请联系管理员。
原文链接:基于lucene的案例开发:IndexSearcher中检索方法,转载请注明来源!