声明
1、 刚刚开始学习爬虫,写这个纯属兴趣,代码会有很多不严谨
2、 如果要转载,请标记出来源
爬取网站:顶点小说
获取书库资源
1、先查找搜索时的规律:
搜索大道朝天时网站为:https://www.118book.com/book/39/,代号39
搜索永恒圣王时网站为:https://www.118book.com/book/10393/,代号10393
可以得出每一个数字都代表一本书,因此可以使用循环获取某个范围内的所有书名
2、查看网页源代码,查找书名位置,从以下图片可以看出,书名位于id为info的div标签中的h1标签中

3、建立一个字典bookNames,来存放书名以及对应的编号
代码如下:

import requests
from bs4 import BeautifulSoup
import bs4
bookNames = {}
def getBookName(bookNames, number):
for i in range(number):
url = 'https://www.118book.com/book/'+str(i)
try:
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup=BeautifulSoup(demo,'html.parser')
for tag in soup.find(id='info').children:
if(tag.name=='h1'):
bookNames[i]=tag.string
except:
print("爬取失败")
getBookName(bookNames, 3)
print(bookNames)
输出结果:
{0: '我们是洪荒玩家', 1: '超级募兵仓库', 2: '僵君令'}
搜索指定书名
搜索书名是在bookNames字典中查找,如果存在返回书籍的编号,否则返回-1
def searchBook(bookNames):
name = input("输入要搜索的书名:")
id = -1
for key, value in bookNames.items():
if name == str(value):
id = key
return id
getBookName(bookNames, 3)
print(bookNames)
id = searchBook(bookNames)
print(id)
注: 循环中valuse的类型是 'bs4.element.NavigableString,而name的类型是String,比较是否相等时要进行类型转换,否则一直返回-1
结果:
{0: '我们是洪荒玩家', 1: '超级募兵仓库', 2: '僵君令'}
输入要搜索的书名:僵君令
2
获取书籍的章节目录
1、该方法要获取书籍的章节目录以及每一章节对应的网址,并将其保存,为之后的书籍下载做准备这一部分应该是最重要的地方
2、分析网页源码
从网页源码中可以看出,每一个class为_chapter中包含3个小章节,所有要获取所有的class为_chapter的ul,然后再遍历其中的子节点
注: 这里有关问题class是python的关键字,不能在这里使用只能先获取id为list的div,然后在获取ul
代码
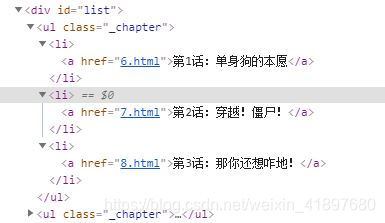
def getChapter(chapters, bookNames):
id = searchBook(bookNames)
url = 'https://www.118book.com/book/'+str(id)
try:
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
string=''
print(type(demo))
for uls in soup.find(id='list').children: # 获取所有的ul
string+=str(uls) # 注意类型
soup=BeautifulSoup(string,'html.parser')
for a in soup.find_all('a'): # 获取所有a标签
chapters[a.attrs['href']]=a.string # 注意href是a标签的一个属性,不能直接a.href
except:
print("章节获取失败")
bookNames = {} # 存储获取的所有书名
chapters = {} # 存储指定小说的章节
getBookName(bookNames, 3)
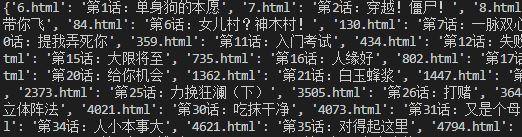
getChapter(chapters, bookNames)
print(chapters)
结果:
下载小说
1、最后一个阶段将小说保存的本地,想法是小说名作为文件名,每一章节都是一个单独的以章节名为命名的txt文件
2、随便打开一个章节,可以得到网址,例如:https://www.118book.com/book/2/6.html,可以得出规律只需要在https://www.118book.com/book/2/拼接上对应的编号即可打开每一章节
3、查看源代码,获取小说内容所在的标签
从源代码中可以看出只需要获得id为content的div标签即可

def saveNovel(bookNames, chapters, flog):
i = -1
id = searchBook(bookNames)
getChapter(chapters, bookNames, id)
url = 'https://www.118book.com/book/'+id+'/'
for key, value in chapters.items():
i += 1
if(flog == True and i == 3):
break
try:
href = url+key
r = requests.get(href, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
div = soup.find_all(id='content')
text = (str(div)).replace('<br/>', '\n') # 替换换行符的形式
path = 'D:/'+bookNames[int(id)] # 存放小说的文件夹
if not os.path.exists(path): # 检测文件夹是否存在
os.mkdir(path)
file = open(path+'/'+value+'.txt', 'a', encoding="utf-8")
file.write(text)
file.close()
except Exception as re:
print(re)
print("下载完成")
注: 如果只是单纯下载某一个页面的小说可以使用以下代码
import requests
from bs4 import BeautifulSoup
import bs4
import os
url = 'https://www.118book.com/book/2/6.html' # 这是每一章节对应的网址
try:
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
div = soup.find_all(id='content')
div = (str(div)).replace('<br/>', '\n')
path = 'D:/'+'1'
file=open(path+'/a.txt','a',encoding="utf-8")
file.write(div)
file.close()
print('wc')
except Exception as re:
print(re)
完整代码
偷个懒,代码还可以简单整理以下,就不整理了
1、可以加一个main函数
2、以下代码有些重复,可以单独定义成一个init函数
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
3、完整代码:
import requests
from bs4 import BeautifulSoup
import bs4
import os
# 获取书库
def getBookName(bookNames, number):
for i in range(number):
url = 'https://www.118book.com/book/'+str(i)
try:
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
for tag in soup.find(id='info').children:
if(tag.name == 'h1'):
bookNames[i] = tag.string
except:
print("爬取失败")
# 搜索指定书籍
def searchBook(bookNames):
name = input("输入要搜索的书名:")
id = -1
for key, value in bookNames.items():
if name == str(value):
id = key
return str(id)
# 获取所有的章节
def getChapter(chapters, bookNames, id):
url = 'https://www.118book.com/book/'+id
try:
r = requests.get(url, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
string = ''
for uls in soup.find(id='list').children: # 获取所有的ul
string += str(uls) # 注意类型
soup = BeautifulSoup(string, 'html.parser')
for a in soup.find_all('a'): # 获取所有a标签
# 注意href是a标签的一个属性,不能直接a.href
chapters[a.attrs['href']] = a.string
except:
print("章节获取失败")
# 下载小说
def saveNovel(bookNames, chapters, flog):
i = -1
id = searchBook(bookNames)
getChapter(chapters, bookNames, id)
url = 'https://www.118book.com/book/'+id+'/'
for key, value in chapters.items():
i += 1
if(flog == True and i == 3):
break
try:
href = url+key
r = requests.get(href, timeout=30)
r.raise_for_status
r.encoding = r.apparent_encoding
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
div = soup.find_all(id='content')
text = (str(div)).replace('<br/>', '\n') # 替换换行符的形式
path = 'D:/'+bookNames[int(id)] # 存放小说的文件夹
if not os.path.exists(path): # 检测文件夹是否存在
os.mkdir(path)
file = open(path+'/'+value+'.txt', 'a', encoding="utf-8")
file.write(text)
file.close()
except Exception as re:
print(re)
print("下载完成")
bookNames = {} # 存储获取的所有书名
chapters = {} # 存储指定小说的章节
getBookName(bookNames, 3)
print(bookNames)
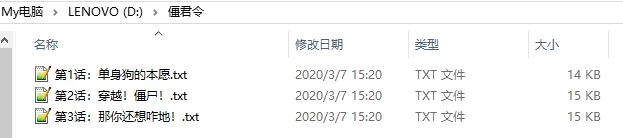
saveNovel(bookNames, chapters, True)
注: 因为运行速度有些慢,当soveNovel的参数为true时,只下载3章,如果要全部下载设置为false即可
运行结果:



总结
1、 感觉写这个程序非常累,写了很久
2、 写程序过程中发现自己不扎实,要翻书、看笔记
3、 要注意类型,代码因为类型问题,出现了很多错误
转载自原文链接, 如需删除请联系管理员。
原文链接:爬虫 (7)—— 爬取网络小说,详细分析及代码,转载请注明来源!