目的
分析某行业中,用户最关心的一些需求,再根据这一需求去调整站内TDK,以及一些频道、内容的规划
过程
1、下载安装cygwin:http://www.cygwin.com/
2、cygwin安装时别忘记安装curl,wget,iconv,lynx,dos2unix,Python等常用工具,特别是Python,这次主要就是用它了。
首选:https://github.com/fxsjy/jieba/archive/master.zip
备用:https://pypi.python.org/pypi/jieba/
4、安装jieba中文分词组件:
全自动安装: easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 https://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
通过 import jieba 来引用
5、复制以下代码,另存为“jiebacmd.py”
6、新建一个文件夹,将你需要分词的文本和jiebacmd.py拷进去,记住文本需要另存为utf-8编码,然后在cygwin里用cd命令把工作目录切换进新建的文件夹,再输入以下命令:cat abc.txt|python jiebacmd.py|sort|uniq -c|sort -nr|head -100
#encoding=utf-8 #usage example (find top 100 words in abc.txt): #用途:找出abc.txt文件中出现频率最高的前100个词 #复制以下命令到cygwin里运行,abc.txt是你文本的文件名,head -100可以自己改成想要提取的前多少个词 #cat abc.txt | python jiebacmd.py | sort | uniq -c | sort -nr -k1 | head -100 #以上都是注释,不影响程序运行 from __future__ import unicode_literals import sys sys.path.append("../") reload(sys) sys.setdefaultencoding( "utf-8" ) import jieba default_encoding='utf-8' if len(sys.argv)>1: default_encoding = sys.argv[1] while True: line = sys.stdin.readline() if line=="": break line = line.strip() for word in jieba.cut(line): print(word)
结果
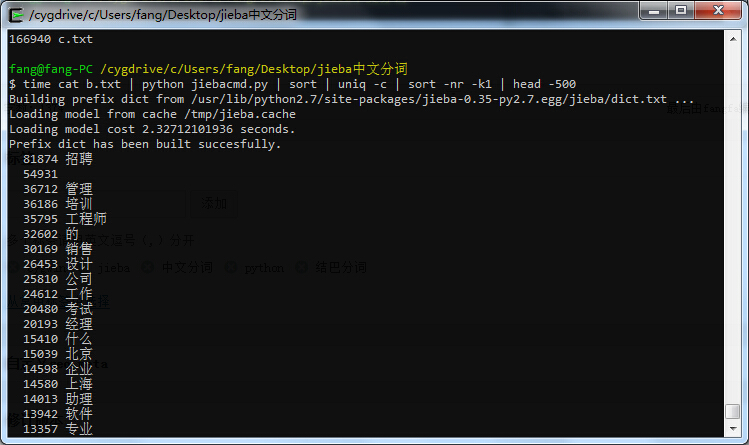
效果如下图,完成16万个关键词的分词、去重、按关键词的出现次数排序、取出现次数最多的前10个词,只花了18秒。


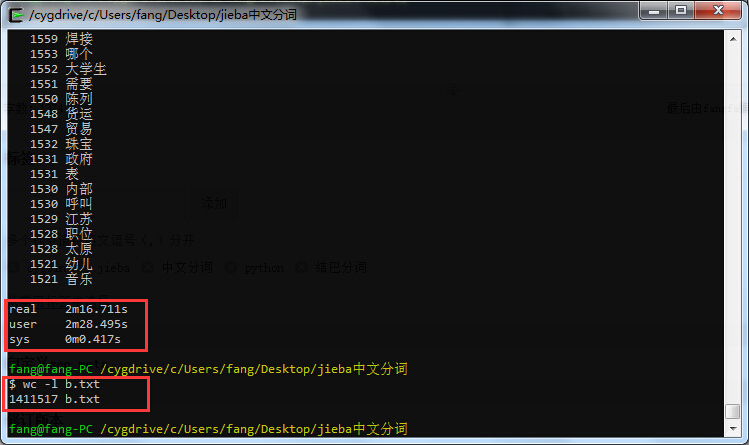
再来试个140万的词库,用时不到2分半:
补充
另有一示例脚本,也是提取高权重词的,貌似比上面的脚本更准确,代码如下:
import sys sys.path.append('../') import jieba import jieba.analyse from optparse import OptionParser USAGE = "usage: python extract_tags.py [file name] -k [top k]" parser = OptionParser(USAGE) parser.add_option("-k", dest="topK") opt, args = parser.parse_args() if len(args) < 1: print(USAGE) sys.exit(1) file_name = args[0] if opt.topK is None: topK = 10 else: topK = int(opt.topK) content = open(file_name, 'rb').read() tags = jieba.analyse.extract_tags(content, topK=topK) print("\n".join(tags))
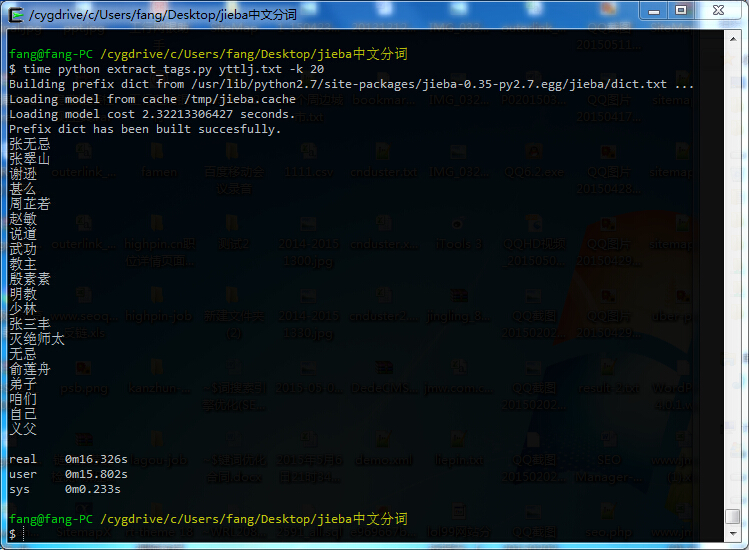
复制代码另存为extract_tags.py,使用方式为在cygwin下面输入python extract_tags.py yttlj.txt -k 20,yttlj.txt是《倚天屠龙记》这部小说,统计里面出现次数最多的词,取前20名,结果如下:
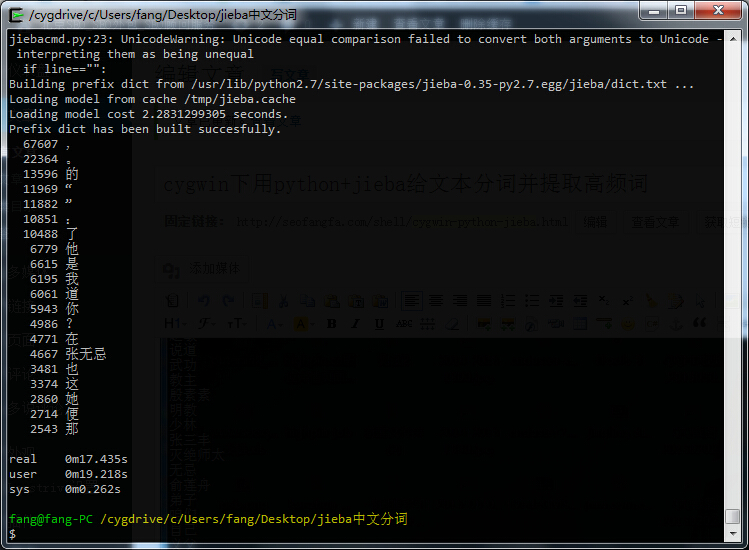
如果用一开始给的那个代码,将得到如下结果,可以看到,标点符号和停止词(stop words)都分出来,所以感觉还是上面那个结果更靠谱一些。
转载自:方法SEO顾问 » cygwin下用Python+jieba给文本分词并提取高频词
原文链接:cygwin下用Python+jieba给文本分词并提取高频词,转载请注明来源!