本讲针对的题型是数据型的建模问题, 2012 年的 A 题就是一道典型这类问题,接下来将介绍这道题的 MATLAB 求解过程。
1. 问题的提出
确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。附件 1 给出了某一年份一些葡萄酒的评价结果,附件 2 和附件 3 分别给出了该年份这些葡萄酒的和酿酒葡萄的成分数据。请尝试建立数学模型讨论下列问题:
1. 分析附件1中两组评酒员的评价结果有无显著性差异,哪一组结果更可信?
2. 根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。
3. 分析酿酒葡萄与葡萄酒的理化指标之间的联系。
4. 分析酿酒葡萄和葡萄酒的理化指标对葡萄酒质量的影响,并论证能否用葡萄和葡萄酒的理化指标来评价葡萄酒的质量?
附件1:葡萄酒品尝评分表(含4个表格)
附件2:葡萄和葡萄酒的理化指标(含2个表格)
附件3:葡萄和葡萄酒的芳香物质(含4个表格)
说明: 问题提出部分的附件请参考官网原题。
2. 问题 1 模型的建立和求解
2.1 问题 1 的分析
问题 1 要求我们首先首先要确定两组评酒员的评价结果有无显著性差异,再评判哪组结果更可信。既然是显著性差异,我们很容易就想到可以用统计学中的显著性检验方法来确定该问题。
显著性检验(test of significance)又叫假设检验,是统计学中一个很重要的内容。显著性检验的方法很多,常用的有 T 检验、F 检验和 c2 检验等。尽管这些检验方法的用途及使用条件不同,但其检验的基本原理是相同的。根据本问题的场景,结合以上三个检验方法的特点,该问题比较适合用 T 检验方法。
T 检验分为单总体检验和双总体检验。单总体 T 检验时检验一个样本平均数与一个已知的总体平均数的差异是否显著;双总体 T 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。对于该问题,由于有两个样本,因此可以采用双总体 T 检验。
2.2 模型的建立和求解
2.2.1 差异显著性评判
由于 T 检验是比较成熟的方法,所以这里将不再对 T 检验的理论进行探讨,而是直接应用该方法。
双总体 t 检验的一般步骤为:
(1)提出无效假设与备择假设:H0:μ1 = μ2,HA:μ1 ≠ μ2
(2)计算 t 值,计算公式为:


自由度:df = (n1 - 1)+(n2 - 1)

其中,
当 n1 = n2 = n时,

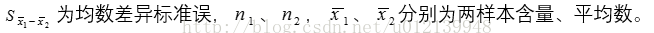
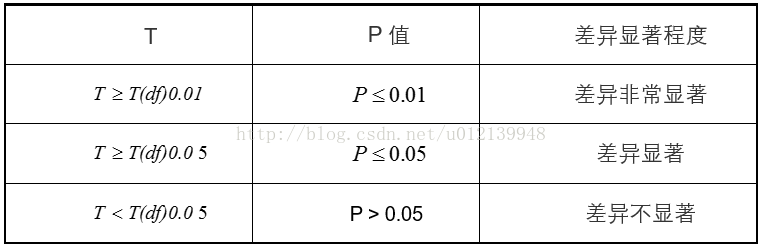
(3)根据 df = (n1-1)+(n2-1),查临界 t 值:t0.05、t0.01,将计算所得 t 值的绝对值与其比较,作出统计推断,推断依据如下所示。
表1 T检验推断依据表
方法确定后,我们再来确定研究对象,即对哪个主体利用该方法,因为这个问题里面,对于每个样品既有单项评分,又有总分,而从品酒员角度,每个品酒员又有评分。为此,我们针对问题的目标,即评判两组评酒员的评价结果有无显著性差异,来确定最合适的研究对象。
在该问题中,每个样品的品质可以认为是固定的,所以对每个样品,不同组品酒员的总分应用 T 检验最合适,也最能反应两组品酒员的评价结果。
为此,在利用 T 检验之前,需要对原始数据进行一些预处理,主要处理内容包括:
(1) 数据质量检查与清洗,即查看数据是否有缺失,如果有缺失,则需要进行填充。通过检查数据质量发现,的确存在数据缺失现象,为此对于缺失的值,用同组的平均值来进行填充。
(2) 对各个 sheet 中的数据按照样品编号进行重新排列,以便利用程序进行比较。
经过这样的处理,就可以用程序来计算这些样品的 T 检验值了, 这样就可以用每组检验值的平均值来表示每组品酒师对红酒和白酒的显著性差异,即:

其中,T* 为平均 T 检验值,i 为样品号,N 为样品总数,Ti 为两组品酒师对样品 i 的 T 检验值。
由于红酒和白酒品质差异比较大,所以我们将分别对红酒和白酒的评价结果进行显著性分析,及对于红酒来说,N=27,对白酒来说,N=8。
至此就可以用 MATLAB 编写程序来求解该问题了,具体程序如下:
%% 2012A_question1_T evaluation
%————————————————————————–
%% 数据准备
% 清空环境变量
clear all
clc
%导入数据
X1=xlsread(’2012A_T1_processed.xls’, ‘T1_red_grape’, ‘D3:M272’);
X2=xlsread(’2012A_T1_processed.xls’, ‘T2_red_grape’, ‘D3:M272’);
X3=xlsread(’2012A_T1_processed.xls’, ‘T1_white_grape’, ‘D3:M282’);
X4=xlsread(’2012A_T1_processed.xls’, ‘T2_white_grape’, ‘D3:M282’);
%% 红葡萄酒T检验计算过程
[m1,n1]=size(X1);
K1=27;
% 计算每个样品的总得分
for i=1:K1
for j=1:n1
SX1(i,j)=sum(X1(10*i-9:10*i,j));
SX2(i,j)=sum(X2(10*i-9:10*i,j));
end
end
% 计算每组样品得分的均值
for i=1:K1
Mean1(i)=mean(SX1(i,:));
Mean2(i)=mean(SX2(i,:));
end
% 计算检验值
for i=1:K1
S1(1,i)=(sum((SX1(i,:)-Mean1(i)).^2)+sum((SX2(i,:)-Mean2(i)).^2))/(n1*(n1-1));
T1(1,i)=(Mean1(i)-Mean2(i))/(sqrt(S1(1,i)));
end
AT_R=abs(T1);
M_AT_R=mean(AT_R);
%% 白葡萄酒T检验计算过程
[m2,n2]=size(X3);
K2=28;
% 计算每个样品的总得分
for i=1:K2
for j=1:n2
SX3(i,j)=sum(X3(10*i-9:10*i,j));
SX4(i,j)=sum(X4(10*i-9:10*i,j));
end
end
% 计算每组样品得分的均值
for i=1:K2
Mean3(i)=mean(SX3(i,:));
Mean4(i)=mean(SX4(i,:));
end
% 计算检验值
for i=1:K2
S2(1,i)=(sum((SX3(i,:)-Mean3(i)).^2)+sum((SX4(i,:)-Mean4(i)).^2))/(n2*(n2-1));
T2(1,i)=(Mean3(i)-Mean4(i))/(sqrt(S2(1,i)));
end
AT_W=abs(T2);
M_AT_W=mean(AT_W);
%% 结果显示与比较
a=2.102; % T(0.05,2,18)=2.101
b=2.878; % T(0.01,2,18)=2.878
set(gca,’linewidth’,2)
% 红酒结果
for i=1:K1
Ta1(i)=a;
Tb1(i)=b;
end
t1=1:K1;
subplot(2,1,1);
plot(t1,AT_R,’*k-‘,t1,Ta1,‘r-‘,t1,Tb1,‘-.b’, ‘LineWidth’, 2)
title(’红酒显著性检验结果’,‘fontsize’,14)
legend(’T检验值’, ‘T(0.05)值’, ‘T(0.01)值’)
xlabel(’样品号’), ylabel(‘T检验值’)
% 白酒结果
for i=1:K2
Ta2(i)=a;
Tb2(i)=b;
end
t2=1:K2;
subplot(2,1,2);
plot(t2,AT_W,’*k-‘,t2,Ta2,‘r-‘,t2,Tb2,‘-.b’, ‘LineWidth’, 2)
title(’白酒显著性检验结果’,‘fontsize’,14)
legend(’T检验值’, ‘T(0.05)值’, ‘T(0.01)值’)
xlabel(’样品号’), ylabel(‘T检验值’)
% 显示平均检验结果
disp([’两组品酒师对红酒的平均显著性T检验值:’ num2str(M_AT_R)]);
disp([’两组品酒师对白酒的平均显著性T检验值:’ num2str(M_AT_W)]);
%% end
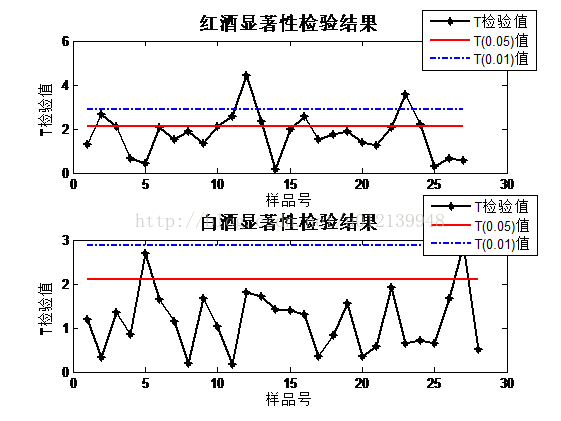
图 1 每个样品的 T 检验值与参考值的比较
运行程序,得到每个样品的 T 检验结果(如图 1 所示)和平均 T 检验值:
两组品酒师对红酒的平均显著性 T 检验值:1.7539
两组品酒师对白酒的平均显著性 T 检验值:1.1641
查表可知, T(0.05,2,18) = 2.101, T(0.01,2,18) = 2.878。按照 T 检验的第三步,可知,T < T(df)0.05,所以我们可以得到这样的问题 1 的结论:
(1) 两组品酒师对红酒和白酒的评价结果差异都不显著;
(2) 对白酒评价结果的差异小于对红酒的差异。
2.2.2 评价结果稳定性
基于上面的分析,我们可知,两组品酒师对酒样的评判结果差异不显著,即可以认为来自于同个样本的数据。这样我们就可以用每组品酒师的得分对总体样本的方差来表示各组品酒师评价结果的稳定性了,即:
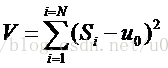
其中,V 为样本对总体样本的方差,Si 为第 i 品酒师的给酒样的总分,u0 为总体样本均值。
由于在计算 T 检验的过程中,已得到该表达式中的所有参数的值,所以可以很快得到每组品酒师对每个样品的方差了。在上面程序的基础上,稍作修改,就可以编写出计算该方差的程序如下:
%% 2012A_question1_T evaluation
%————————————————————————–
%% 数据准备
% 清空环境变量
clear all
clc
%导入数据
X1=xlsread(’2012A_T1_processed.xls’, ‘T1_red_grape’, ‘D3:M272’);
X2=xlsread(’2012A_T1_processed.xls’, ‘T2_red_grape’, ‘D3:M272’);
%% 计算每组品酒师对每个样品的方差
[m,n]=size(X1);
K=27;
% 计算每个样品的总得分
for i=1:K
for j=1:n
SX1(i,j)=sum(X1(10*i-9:10*i,j));
SX2(i,j)=sum(X2(10*i-9:10*i,j));
end
u0(i)=mean([SX1(i,:), SX2(i,:)]);
end
% 计算方差
for i=1:K
SD1(i,:)=(SX1(i,:)-u0(i)).*(SX1(i,:)-u0(i));
SD2(i,:)=(SX2(i,:)-u0(i)).*(SX2(i,:)-u0(i));
end
%% 结果显示与比较
for i=1:K
TSD(1,i)=sum(SD1(i,:));
TSD(2,i)=sum(SD2(i,:));
end
t=1:K;
plot(t,TSD(1,:),’*k-‘,t,TSD(2,:),‘or–’, ‘LineWidth’, 2)
legend(’一组对红酒方差’,‘二组对红酒方差’)
xlabel(’红酒样品编号’); ylabel(‘红酒样品编号’);
TSD1=sum(TSD(1,:));
TSD2=sum(TSD(2,:));
disp([’一组对红酒总方差:’ num2str(TSD1)]);
disp([’二组对红酒总方差:’ num2str(TSD2)]);
运行该程序,可得到如图 2 所示的两组品酒师对各个红酒样品的方差,同时得到总方差:
一组总方差:16434.675
二组总方差:10524.775
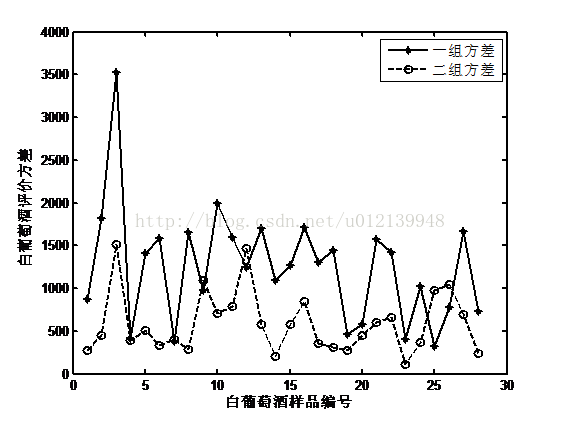
图 2 两组品酒师品酒数据方差比较(白葡萄酒)
由于方差越小,说明越稳定,故对于红酒来说,第二组品酒师的评价结果更稳定。
同样,将以上程序的输入数据改为白酒的数据,则可以得到两组品酒师对白葡萄酒样品的方差变化趋势(如图 3)和总方差:
一组对白葡萄酒总方差:34961.6
二组对白葡萄酒总方差:16522.8
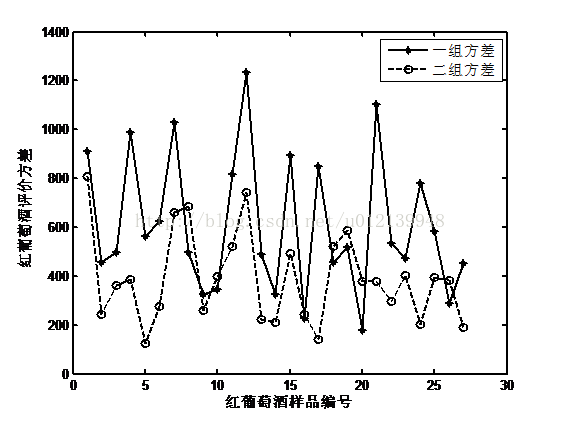
图 3 两组品酒师品酒数据方差比较(红葡萄酒)
综合两组对两类葡萄酒的评价稳定性,可知第二组对两类酒评价的稳定性都比第一组高。
3. 问题 2 模型的建立和求解
3.1 问题 2 的基本假设和分析
3.1.1 基本假设
(1) 假设评酒员在完全相同的环境因素下进行评酒, 且评酒员均按照同一标准进行评酒。
(2) 假设酿酒葡萄的编号和葡萄酒的编号是一致的,存在严格的对应关系。这样就可以利用葡萄酒的评分数据对酿酒葡萄进行分级,同时两者的理化指标也能够对应上,便于找出它们在理化指标方面的关系。
3.1.2 问题 2 的分析
问题 2 要求根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。但该问题中并没有给分级的标准和具体的分级数,所以该问题属于数据建模中的聚类问题。这样我们就可以利用一些聚类方法来求解该问题了。在众多聚类方法中,K-means 方法算法适应性比较强的方法,所以不妨先用 K-means 方法对所研究的数据进行聚类,然后还可以尝试用层次聚类、模糊聚类等方法, 以便于结果的比较和最佳聚类方法的选择。
下面我们就要来分析该对谁聚类,也就是说要来确定聚类的研究对象。问题中已明确规定根据酿酒葡萄的理化指标和葡萄酒的质量来实现对酿酒葡萄的分级。对葡萄酒的理化指标数据分析发现,理化指标比较多,用哪些指标是进行分级效果很难评判。但用葡萄酒质量数据来进行分级,既有直观的现实意义,操作性也比较可行,为此,可以先根据葡萄酒的质量来进行酿酒葡萄的分级。由第一问,可知,虽然第二组品酒师的数据更稳定,但两组品酒师的结果并没有显著差异,所以,应该以两组品酒师的平均值作为酒样的质量数据。
当根据葡萄酒的质量对酿酒葡萄进行分级后,然后就可以研究如何利用酿酒葡萄的理化指标来分级。这里面,由于理化指标的差异就是数值上的差异,而求解这类问题的一个典型的方法就是 PCA 方法,所以可以用 PCA 方法来实现对理化指标的降维,然后同样可以用上述的聚类方法来实现聚类。
3.2 模型的建立和求解
3.2.1 葡萄酒质量分级
目前的聚类算法都属于半监督算法, 还需要指定每次聚类过程中类别的数量, 所以对于该问题, 需要先确定最佳类别的数量。可以先用轮廓值对 K-means 方法得到的聚类结果进行评价, 这样就可以据此来确定最佳的类别数。
此处,对于聚类的执行选择由 K-means 方法来实现,是因为该算法的适应范围最广。K-means 算法的一般步骤如下:
(1) 从 n 个数据对象任意选择 k 个对象作为初始聚类中心;
(2) 循环 (3) 到 (4) 直到每个聚类不再发生变化为止;
(3) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(4) 重新计算每个(有变化)聚类的均值(中心对象),直到聚类中心不再变化。这种划分使得下式最小:
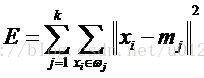
其中,mj为各类的中心。
现在再来明确要聚类的对象。这里可以对理化指标进行聚类, 也可以对葡萄酒的质量(评分)进行聚类,很显然,对后者聚类更容易操作,且还可以以两组品酒师评分的均值作为葡萄酒的质量。现在先以红葡萄酒的质量评分为研究对象,来确定最佳的类别。当确定最佳分类数后就可以同时使用常用的集中聚类方法对该问题进行聚类了, 然后比较各种算法对该问题更合适,同时还可以比较各算法对该问题是否具有很好的一致性。根据上面的思路,编写了 MATLAB 程序:
%% 用聚类法确定葡萄酒分级
clc, clear all, close all
%% 需要聚类的数据
% 红葡萄酒质量评分
A=[79.95 75 80.45 78.15 76.25 71.95 75.85 71.85 76.65…
77.05 71.85 67.84 69.9 74.55 75.4 70.65 79.55 74.9…
74.3 77.2 77.8 75.2 76.65 74.7 78.3 77.8 70.9 80.45];
% 白葡萄酒质量评分
%{
A = [79.95 75 80.45 78.15 76.25 71.95 75.85 71.85 76.6…
77.05 71.85 67.85 69.9 74.55 75.4 70.65 79.55 74.9…
74.3 77.2 77.8 75.2 76.65 74.7 78.3 77.8 70.9];
%}
%% 用k-Means聚类法确定最佳的聚类数
X=A’;
numC=15;
for i=1:numC
kidx = K-means(X,i);
silh = silhouette(X,kidx); %计算轮廓值
silh_m(i) = mean(silh); %计算平均轮廓值
end
figure
plot(1:numC,silh_m,’o-‘)
xlabel(’类别数’)
ylabel(’平均轮廓值’)
title(’ 不同类别对应的平均轮廓值’)
% 绘制2至5类时的轮廓值分布图
figure
for i=2:5
kidx = K-means(X,i);
subplot(2,2,i-1);
[~,h] = silhouette(X,kidx);
title([num2str(i), ’类时的轮廓值 ‘ ])
snapnow
xlabel(’轮廓值’);
ylabel(’类别数’);
end
%% K-means 聚类过程,并将结果显示出来
[idx,ctr]=K-means(A’,4); % 用 K-means 法聚类
% 提取同一类别的样品号
c1=find(idx==1); c2=find(idx==2);
c3=find(idx==3); c4=find(idx==4);
figure
F1 = plot(find(idx==1), A(idx==1),’r–*’, …
find(idx==2), A(idx==2),’b:o’, …
find(idx==3), A(idx==3),’k:o’, …
find(idx==4), A(idx==4),’g:d’);
set(gca,’linewidth’,2);
set(F1,’linewidth’,2, ‘MarkerSize’,8);
xlabel(’编号’,‘fontsize’,12);
ylabel(’得分’,‘fontsize’,12);
title(’白葡萄酒质量评分–K-means聚类结果’)
disp(’聚类结果:’);
disp([’第1类:’ ,‘中心点:’,num2str(ctr(1)),‘ ‘,‘该类样品编号:’, num2str(c1’)]);
disp([’第2类:’ ,’中心点:’,num2str(ctr(2)),‘ ‘,‘该类样品编号:’, num2str(c2’)]);
disp([’第3类:’ ,‘中心点:’,num2str(ctr(3)),‘ ‘,‘该类样品编号:’, num2str(c3’)]);
disp([’第4类:’ ,‘中心点:’,num2str(ctr(4)),‘ ‘,‘该类样品编号:’, num2str(c4’)]);
%% 层次聚类
X=A’;
Y=pdist(X); %计算样品间的欧式距离
Z=linkage(Y, ‘average’); % 利用类平均法创建系统聚类树
cn=size(X);
clabel=1:cn;
clabel=clabel’;
figure
F2 = dendrogram(Z); % 绘制聚类树形图
set(F2,’linewidth’,2);
ylabel(’标准距离’);
%% Fuzzy C-means聚类
X=A’;
[center,U] = fcm(X,4);
Cid1 = find(U(1,:) ==max(U));
Cid2 = find(U(2,:) ==max(U));
Cid3 = find(U(3,:) ==max(U));
Cid4 = find(U(4,:) ==max(U));
figure
F3=plot(Cid1, A(Cid1),’r–*’, …
Cid2, A(Cid2),’b:o’, …
Cid3, A(Cid3),’k:o’, …
Cid4, A(Cid4),’g:d’);
set(gca,’linewidth’,2);
set(F3,’linewidth’,2, ‘MarkerSize’,8);
xlabel(’编号’);
ylabel(’得分’);
title(’Fuzzy C-means聚类聚类结果’)
%% 2012年全国赛A题第二问求解示例程序
运行程序的前两节,就可以得到平均该问题的平均轮廓值与分类数的关系图(图 16-4)和类别为 2-5 时的每类的轮廓至分布图(图-5)。 对于聚类问题,我们一方面希望聚类的数量比较适中,同时希望每个样品的轮廓值尽量高。对这个只有不到 30 样品的样本问题,比较合适的类别墅是 2-5 个,而通过图-4, 可以发现,类别为 2 或者 4 时平均轮廓值比较高,但如果只分 2 类,分级效果不明显,同时由图 5 可以看出,分 2 类时,轮廓至较小的样品相对较多,而分为 4 类时,轮廓至的分布效果更好些。所以综合以上分析,对于这个问题,最佳的类别数选为 4 比较合适。 用同样的方法,对白葡萄就的数据进行分析,可以得到一致的结论。说要注意的是,聚类方法都有一定的随机性,所以每次执行的程序会有一些差异,但总体趋势是一致的。
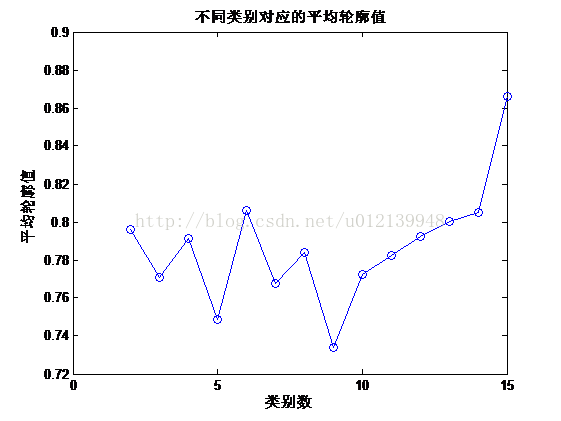
图4 轮廓至与聚类类别数的关系图

图 5 类别为 2-5 时的每类的轮廓至分布图
将类别数设为 4,执行程序的其他几节,就可以分别得到 K-means,层次聚类和模糊-Cmeans 方法的聚类结果了,分别如图 6、图 7 和图 8 所示。从这 3 幅图来看,三种方法的结果基本是一致的,所以说三种方法的对该问题的聚类效果是一致的。所以不妨以 K-means 方法得到的结果作为本问题的分级依据。
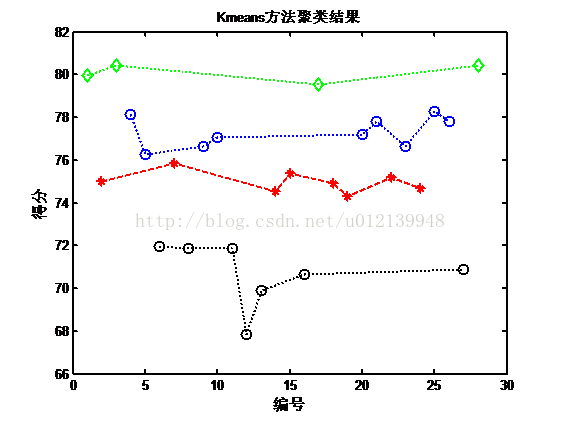
图 6 红葡萄酒 K-mean 方法聚类结果分布图
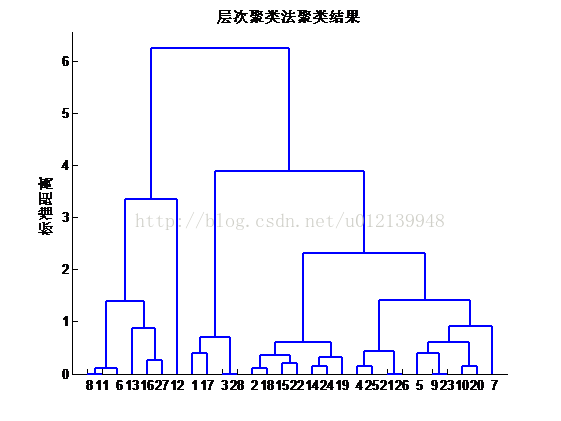
图 7 红葡萄酒层次聚类法聚类结果分布图
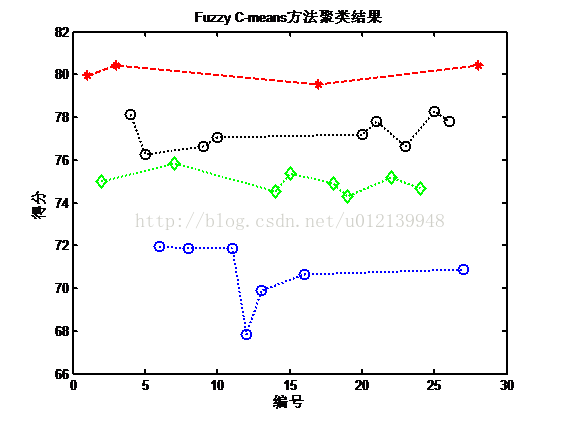
图 8 红葡萄模糊 C-means 聚类法聚类结果分布图
运行该程序,在 MATLAB 的命令窗口区就有 K-means 方法的聚类结果,这样就可以得到红葡萄的分级结果:
红葡萄酒聚类结果:
第1类:中心点:79.0563 该类样品编号:1 3 4 17 21 25 26 28
第2类:中心点:75.6692 该类样品编号:2 5 7 9 10 14 15 18 19 20 22 23 24
第3类:中心点:67.85 该类样品编号:12
第4类:中心点:71.1833 该类样品编号:6 8 11 13 16 27
对于白葡萄酒,可采取同样的方法。利用上面的程序,可以很快得到白葡萄酒的分级结果(白葡萄酒的分类图与红葡萄酒基本一致,所以这里就不在列出,只给出具体的分级结果):
聚类结果:
第1类:中心点:78.4722 该类样品编号:1 3 4 10 17 20 21 25 26
第2类:中心点:75.4045 该类样品编号:2 5 7 9 14 15 18 19 22 23 24
第3类:中心点:67.85 该类样品编号:12
第4类:中心点:71.1833 该类样品编号:6 8 11 13 16 27
4. 关于问题 3 和问题 4 的建模和求解
问题 3 是要分析酿酒葡萄与葡萄酒的理化指标之间的联系,由于两者的理化指标比较多,是多对多的关系,所以给该问题增加了难度。对于这类问题,一般都可以利用拟合、回归、求相关系数这类方法方法来求解。在用方法之间,需要先确定研究的主体,也就是对哪些指标,哪些数据用这些方法。对于这个问题,可以从下面几个角度去展开:
(1) 只研究酿酒葡萄和葡萄酒共有的指标,比如总酚、花色苷,这样,从这个角度,问题就变得非常简单了。接下来,就可以用拟合、回归方法给出两者之间的共有指标的关系了。
(2) 先用 PCA 或方差分析,分别找出酿酒葡萄和葡萄酒的几个主要指标,然后再研究几个主要指标之间的关系。
(3) 求出指标之间的相关系数,筛选相关性比较强的指标,再拟合、回归他们之间的关系。
问题 4 是分析酿酒葡萄和葡萄酒的理化指标对葡萄酒质量的影响,并论证能否用葡萄和葡萄酒的理化指标来评价葡萄酒的质量。该问题是对以上三个问题的总结,综合以上的分类和指标的关系分析,就可以确定葡萄酒质量是否与酿酒葡萄和葡萄酒的理化指标高度相关,如果是,则就可以,而且最好给出,葡萄酒质量与这些理化指标的具体关系,不过不是,则要给出具体的依据,比如相关系数太小。
这两个小问题的具体建模过程和求解因为篇幅原因将不再详细介绍。
5. 点评
葡萄酒的评价问题是典型的数据建模问题,这类建模问题的特点是数据多、可用的方法多,但从建模的角度,难度往往不大。这类问题的求解关键是选对方法、选对数据、用对方法。
本篇论文中,用到了 T 检验、K-means、PCA 等方法,这些方法都是很常见的数学方法,使用难度较低。尽管这些方法很常见,依然出现很多队用错的情况,主要是用错了地方。所以我们平时在学习这些基础建模方法的时候,一定要注意这些方法的使用场景和前提,这样才能灵活地运用这些方法。
通过对这篇论文的解析,我们可以总结出这类数据建模类问题的求解经验:
(1) 明确问题,分析问题,了解与本问题相关的数据信息,并确定求解问题的大致方法(或几种可能的方法);
(2) 分析数据内容,根据求解问题的方向和数据的现实意义等因素,确定研究对象,明确对哪些数据运用方法;
(3) 正确、高效地利用数学工具, 如 MATLAB,实现对问题的求解,并以容易理解的方式直观地将求解结果表现出来。
参考资源
《MATLAB在数学建模中的应用(第二版)》,北航出版社
转载自原文链接, 如需删除请联系管理员。
原文链接:数学建模专栏 | 第十篇:MATLAB CUMCM真题求解实例一:数据型,转载请注明来源!