缓冲区(Buffer)就是在内存中预留指定大小的存储空间用来对输入/输出(I/O)的数据作临时存储,这部分预留的内存空间就叫做缓冲区:
使用缓冲区有这么两个好处:
1、减少实际的物理读写次数
2、缓冲区在创建时就被分配内存,这块内存区域一直被重用,可以减少动态分配和回收内存的次数
举个简单的例子,比如A地有1w块砖要搬到B地
由于没有工具(缓冲区),我们一次只能搬一本,那么就要搬1w次(实际读写次数)
如果A,B两地距离很远的话(IO性能消耗),那么性能消耗将会很大
但是要是此时我们有辆大卡车(缓冲区),一次可运5000本,那么2次就够了
相比之前,性能肯定是大大提高了。
而且一般在实际过程中,我们一般是先将文件读入内存,再从内存写出到别的地方
这样在输入输出过程中我们都可以用缓存来提升IO性能。
所以,buffer在IO中很重要。在旧I/O类库中(相对java.nio包)中的BufferedInputStream、BufferedOutputStream、BufferedReader和BufferedWriter在其实现中都运用了缓冲区。java.nio包公开了Buffer API,使得Java程序可以直接控制和运用缓冲区。
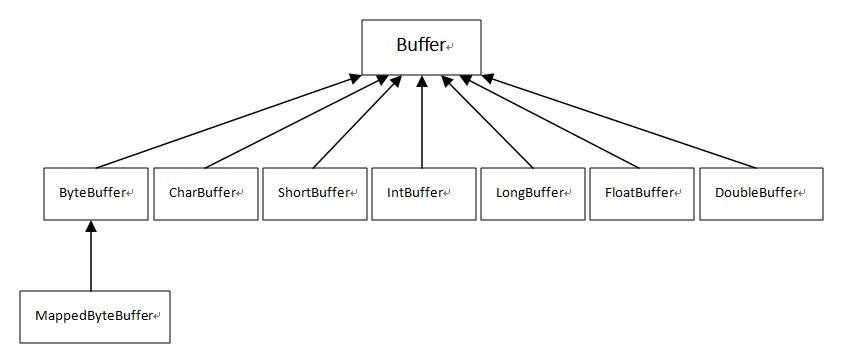
在Java NIO中,缓冲区的作用也是用来临时存储数据,可以理解为是I/O操作中数据的中转站。缓冲区直接为通道(Channel)服务,写入数据到通道或从通道读取数据,这样的操利用缓冲区数据来传递就可以达到对数据高效处理的目的。在NIO中主要有八种缓冲区类(其中MappedByteBuffer是专门用于内存映射的一种ByteBuffer):

Fields
所有缓冲区都有4个属性:capacity、limit、position、mark,并遵循:mark <= position <= limit <= capacity,下表格是对着4个属性的解释:
属性 描述
| Capacity | 容量,即可以容纳的最大数据量;在缓冲区创建时被设定并且不能改变 |
| Limit | 表示缓冲区的当前终点,不能对缓冲区超过极限的位置进行读写操作。且极限是可以修改的 |
| Position | 位置,下一个要被读或写的元素的索引,每次读写缓冲区数据时都会改变改值,为下次读写作准备 |
| Mark | 标记,调用mark()来设置mark=position,再调用reset()可以让position恢复到标记的位置 |
Methods
1、实例化
java.nio.Buffer类是一个抽象类,不能被实例化。Buffer类的直接子类,如ByteBuffer等也是抽象类,所以也不能被实例化。
但是ByteBuffer类提供了4个静态工厂方法来获得ByteBuffer的实例:
方法 描述
| allocate(int capacity) | 从堆空间中分配一个容量大小为capacity的byte数组作为缓冲区的byte数据存储器 |
| allocateDirect(int capacity) | 是不使用JVM堆栈而是通过操作系统来创建内存块用作缓冲区,它与当前操作系统能够更好的耦合,因此能进一步提高I/O操作速度。但是分配直接缓冲区的系统开销很大,因此只有在缓冲区较大并长期存在,或者需要经常重用时,才使用这种缓冲区 |
| wrap(byte[] array) | 这个缓冲区的数据会存放在byte数组中,bytes数组或buff缓冲区任何一方中数据的改动都会影响另一方。其实ByteBuffer底层本来就有一个bytes数组负责来保存buffer缓冲区中的数据,通过allocate方法系统会帮你构造一个byte数组 |
| wrap(byte[] array, int offset, int length) |
在上一个方法的基础上可以指定偏移量和长度,这个offset也就是包装后byteBuffer的position,而length呢就是limit-position的大小,从而我们可以得到limit的位置为length+position(offset) |
我写了这几个方法的测试方法,大家可以运行起来更容易理解