链家北京二手房交易数据分析
项目背景:
基于之前对机器学习,自然语言处理相关内容的学习,并在kaggle上尝试了泰坦尼克号生还者预测,以及Words Meets Bags of Popcorn两个项目的研究,体会到特征工程的重要性,我对数据分析也产生了浓厚的兴趣,对sql进行了集中式的学习之后,以及在阅读过《赤裸裸的统计学》这本书讲解的生活中无处不在的统计学,自己想动手利用所学知识对生活中的数据运用统计学的方法进行分析并得出一些有价值的结论。
收集数据:
在网络上下载链家全网北京二手房数据,通过对这23677条二手房信息的分析与建模来进一步了解这些房源信息。
数据集中相关字段说明:
-
Region:北京的区域
-
Direction:房屋的朝向
-
District:房屋位于的商业区
-
Elevator:房屋是否有电梯
-
Garden:小区名称
-
Id:房屋编号
-
Layout:房屋格局
-
Price:房屋价格
-
Renovation:房屋装修类型
-
Size:房屋的大小
-
Year:房屋的建造年份
明确分析目标
从二手房业务需求的方向,以及自己关心的这些问题,下面从多个维度(区域,房屋的朝向,房屋的价格与大小等)
-
1.分析影响二手房房价的因素
-
2.北京各区二手房的数量与价格分布
数据初探
-
先将csv格式的原始数导入到numbers,并进行初步的观察,了解数据特征的缺失值,异常值,以及大概的描述性统计。

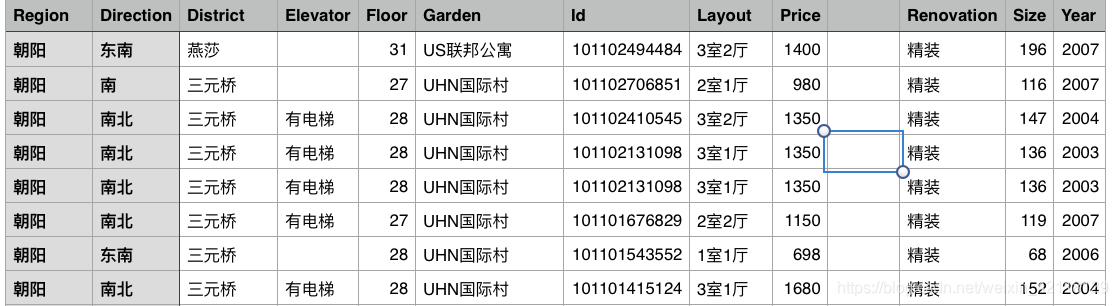
-
初步观察到一共有11个特征变量,Price这里是我们的目标变量,然后进一步的进行观察。
-
将数据导入到spark_sql, 创建数据表。
import csv
with open('lianjia.csv') as f:
reader = csv.reader(f)
rows=[row for row in reader]
for r in rows[1:]:
print '\001'.join(r)
将数据写入 file://Users/liushurui/Desktop/data
- 启动spark_sql
spqrk-sql

use default;
show tables;
CREATE EXTERNAL TABLE lj(
direction STRING,
district STRING,
elevator STRING,
floor STRING,
garden STRING,
id STRING,
layout STRING,
price STRING,
region STRING,
renovation STRING,
size STRING,
year STRING
)
STORED AS TEXTFILE LOCATION 'file:///Users/liushurui/Desktop/data';
- 要查看每个特征变量的缺失值情况以及特征值是数值的一些统计值,包括平均数,标准差,中位数等,用sql需要分别对每一列来进行统计,可以先用python处理来进行概览。
# coding:UTF-8
import pandas as pd
import numpy as np
# 导入数据
lianjia_df = pd.read_csv('~/Desktop/Lianjia.csv')
print lianjia_df.head(n=2)
print lianjia_df.info()
print lianjia_df.describe()
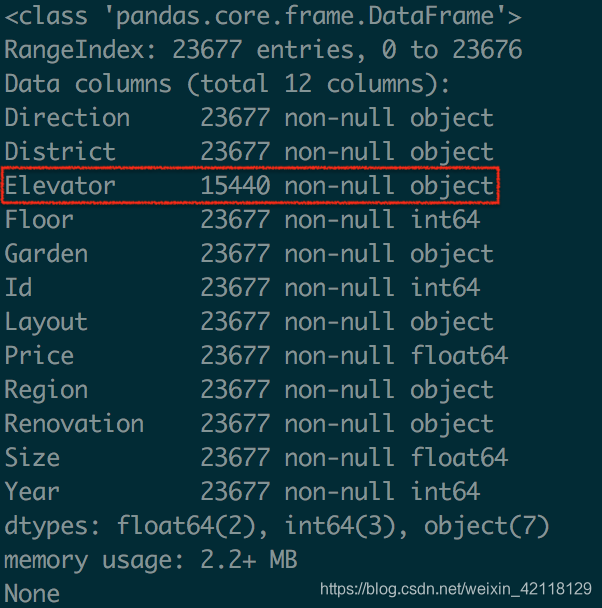
- 总结:一共有23677条数据,其中Elevator特征有明显的缺失值。
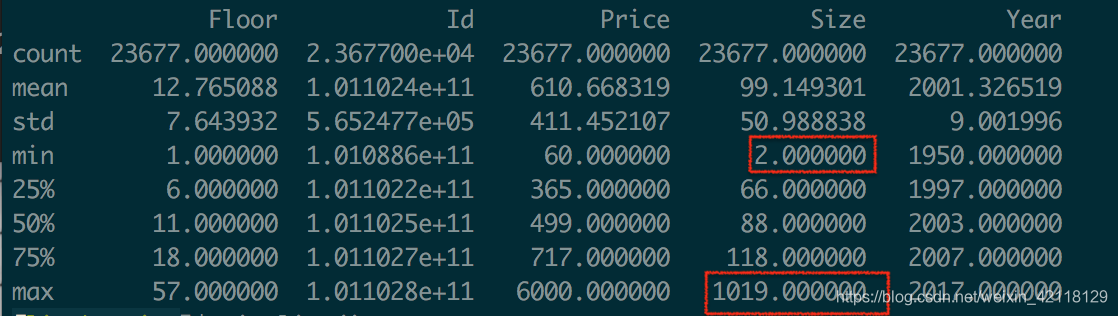
- 总结:上面的结果给出了特征值是数值的一些统计值,包括平均数,标准差,最小值,25%分位数,75%分位数,最大值。这些统计结果简单直接,对于了解一个特征的基本规律非常有用,并且可以根据经验来对一些数据的好坏做出判断,观察到Size特征的最小值为2平方米,最大值为1019平方米,那我们就可以思考这个在实际中是不存在的,可以确定是异常值,在后面分析过程中加以处理,否则会影响模型的性能。
数据可视化
Region特征分析
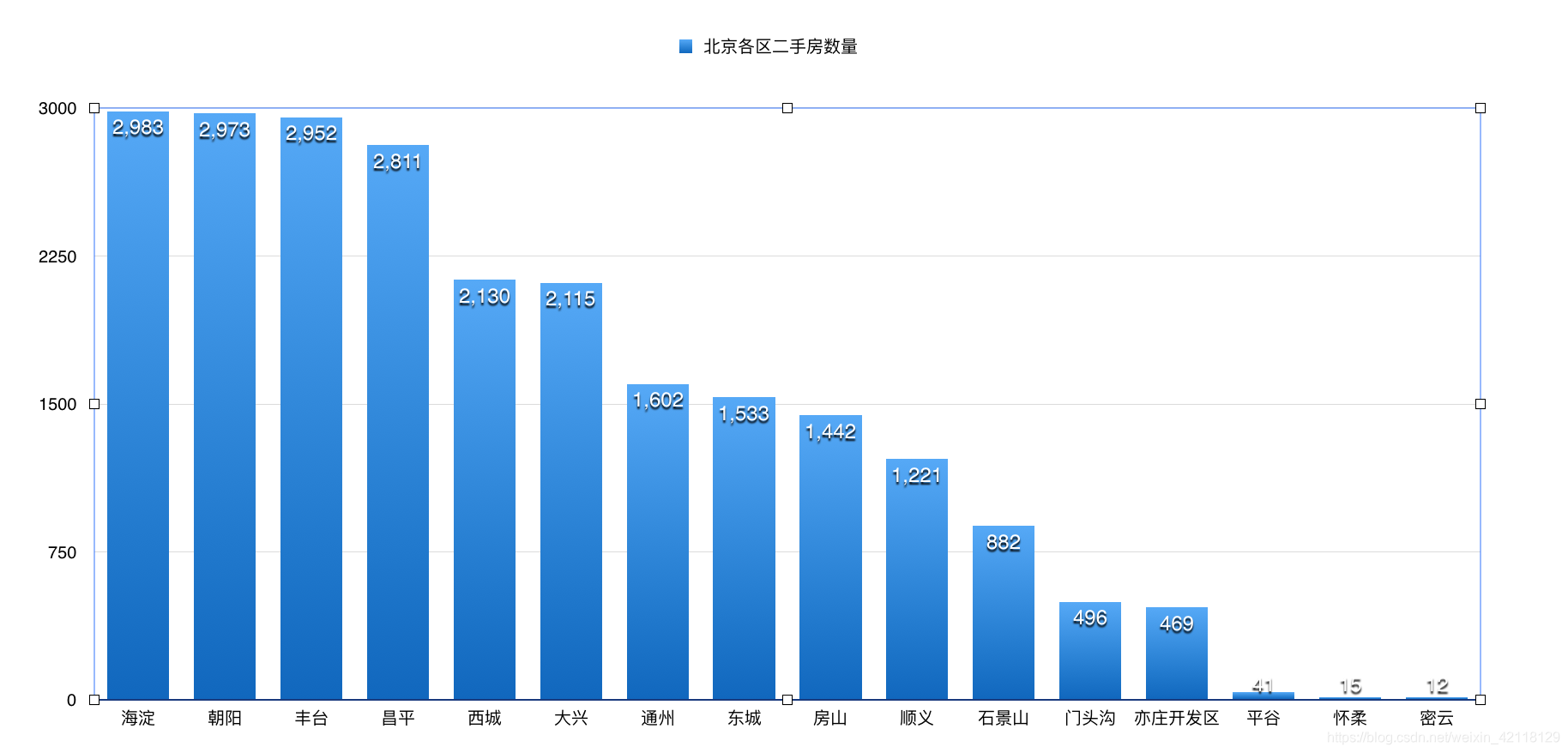
对于区域特征,我们可以分析不同区域的房价和数量的对比。
select region, count(*) c from lj group by region order by c desc;
select r, avg(a) av from (select region r, cast(price as int)/cast(size as int) a from lj) group by r order by av desc;
从以上柱状图可以观察到:
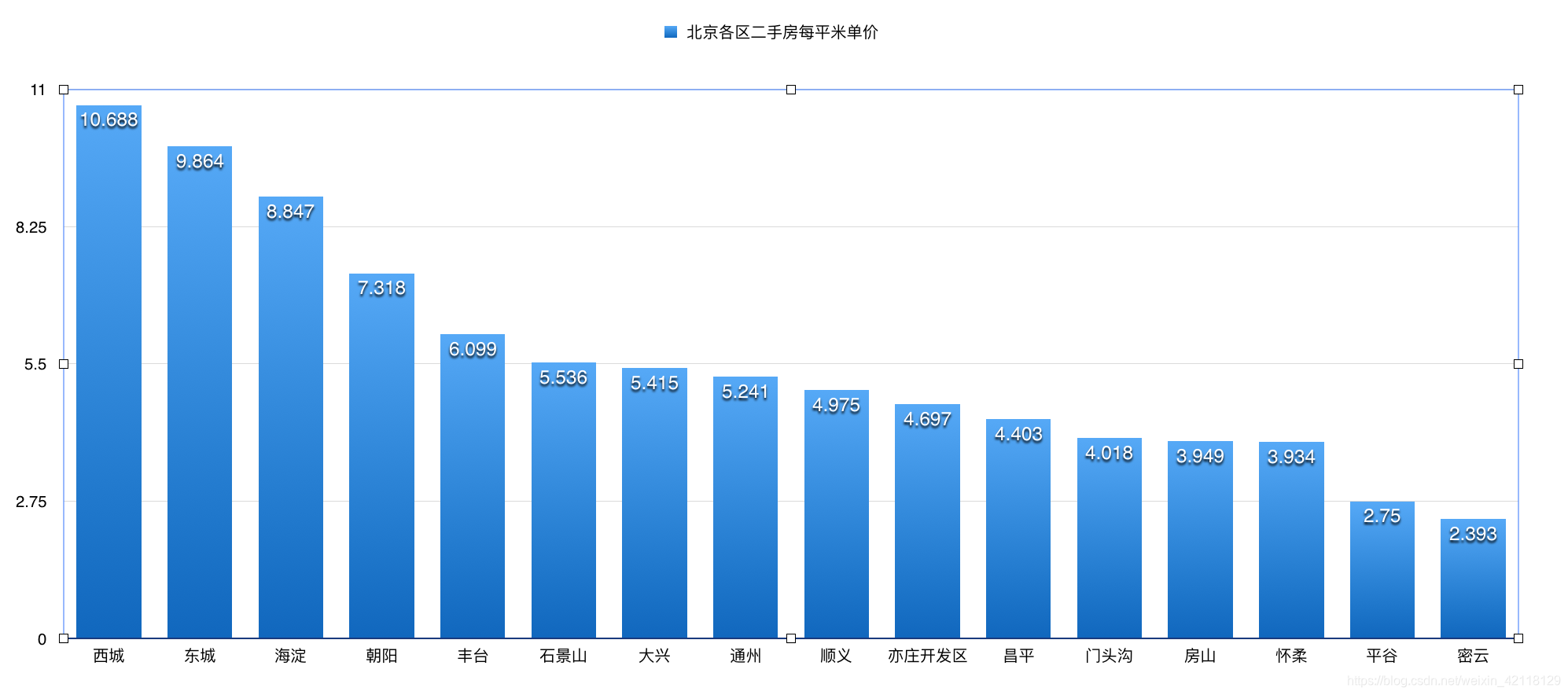
- 北京二手房数量分布:从数量统计上看,目前二手房市场上,海淀区,朝阳区和丰台区的二手房数量最多,接近于3000套,这三个是北京大区,需求量较大。其次是昌平区数量紧随其后。而平谷,怀柔和密云都位于北京五环以外数量非常少。
- 北京二手房均价:从每平米单价的统计分布来看,西城区的房价最贵均价大约11万/平,因为西城在二环里,并且是热门学区房聚集地,其次是东城区大约10万/平,海淀区是8.8万/平,其他几个区的均价都在8万以下。
思考:在计算北京各区二手房每平米单价时,计算均价有两种算法,第一种即上图中是利用每套房子的价格除以它的面积得到每套房子的每平米的单价,然后group by 区域,得到每个区二手房每平米单价的均价,是一种算术平均值算法。第二种是直接求每个区域所有房子的价格总和与面积总和,最后用价格总和除以面积总和,得到每个区二手房每平米单价的均价,是一种加权平均值算法。下面动手尝试第二种算法,并且对比一下两者的结果。
select r, p/s avg from (select region r, sum(price) p, sum(size) s from lj group by region) order by avg desc;
结果对比:
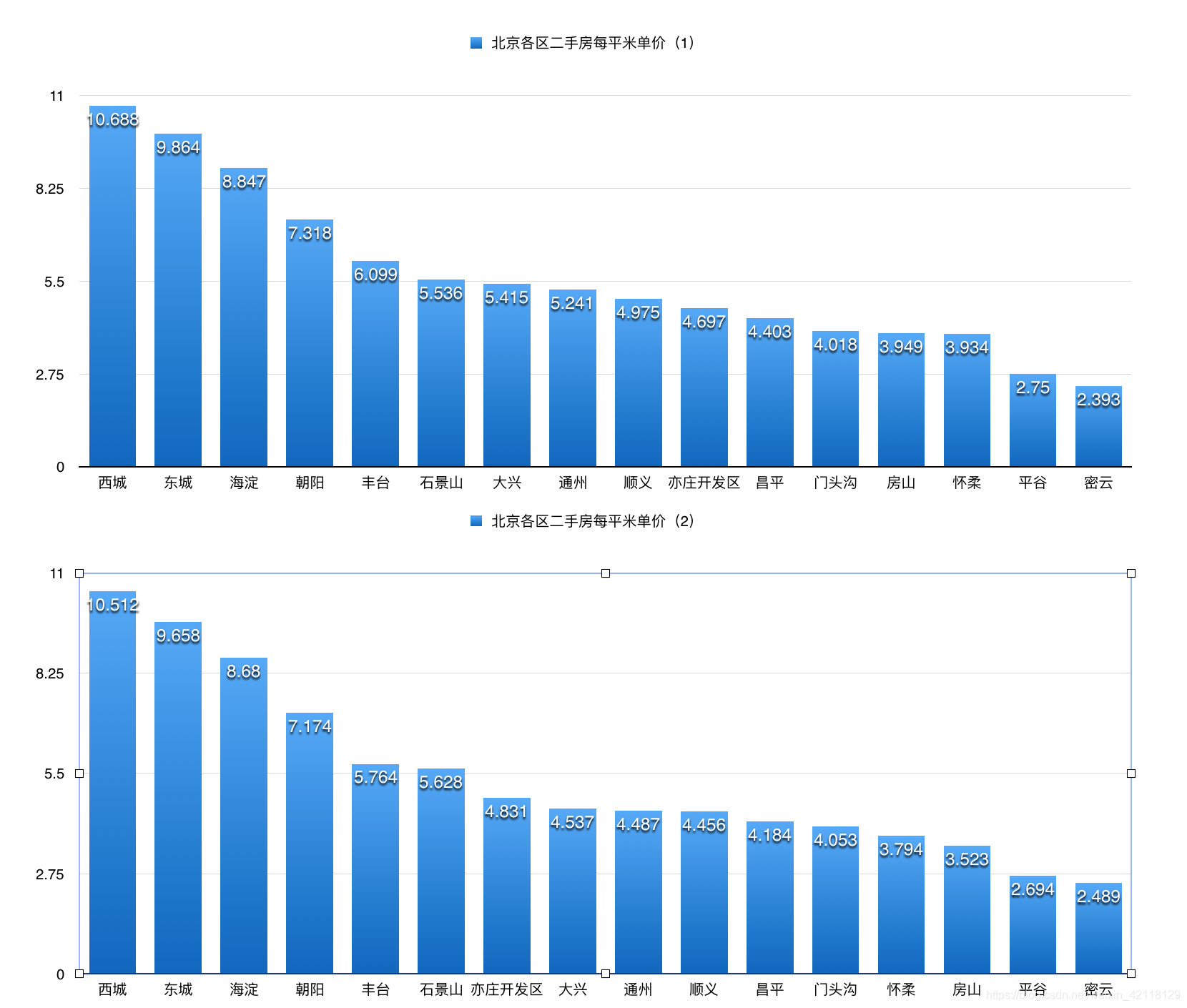
- 结论:两组数据的最终结果相差不多,能证明每个区域的房子大小基本相同。
Size特征分析
对于房屋面积特征,我们可以分析房屋面积的数量分布,以及房屋面积与房屋价格的关系。
size分布
select size s, count(*) from lj group by s order by s;
按照size大小排序后,结果如下:
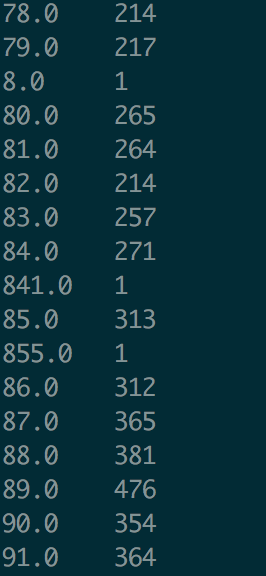
- 问题:上面的运行结果不是我所期待的,排查之后发现,在创建数据表时,所有数据的数据类型均被定义为string类型,所以在排序时也是按照字符串的顺序来排的。
- 解决:在Hive sql 里将string类型转化成为int类型。
select cast(size as int) s, count(*) from lj group by s order by s;
按照size大小排序后,结果如下:
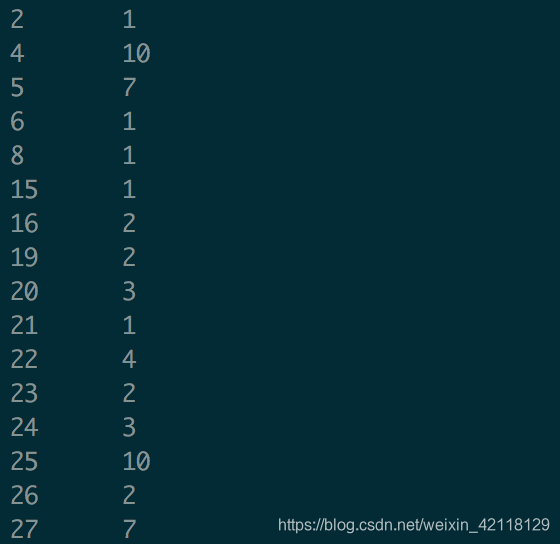
-
总结:对sql的数据类型有了更深的理解。
从上面的折线图发现,房子size的种类太多了,虽然能整体看出大概的趋势,大多数的房子的面积都集中在60-100平方米之间,但是坐标点过于密集,size的过于稀疏,看起来不够直观,再结合机器学习特征处理时,针对于数值型过于稀疏的特征,通常采用数值归一化的处理。接下来尝试归一化,看一下效果。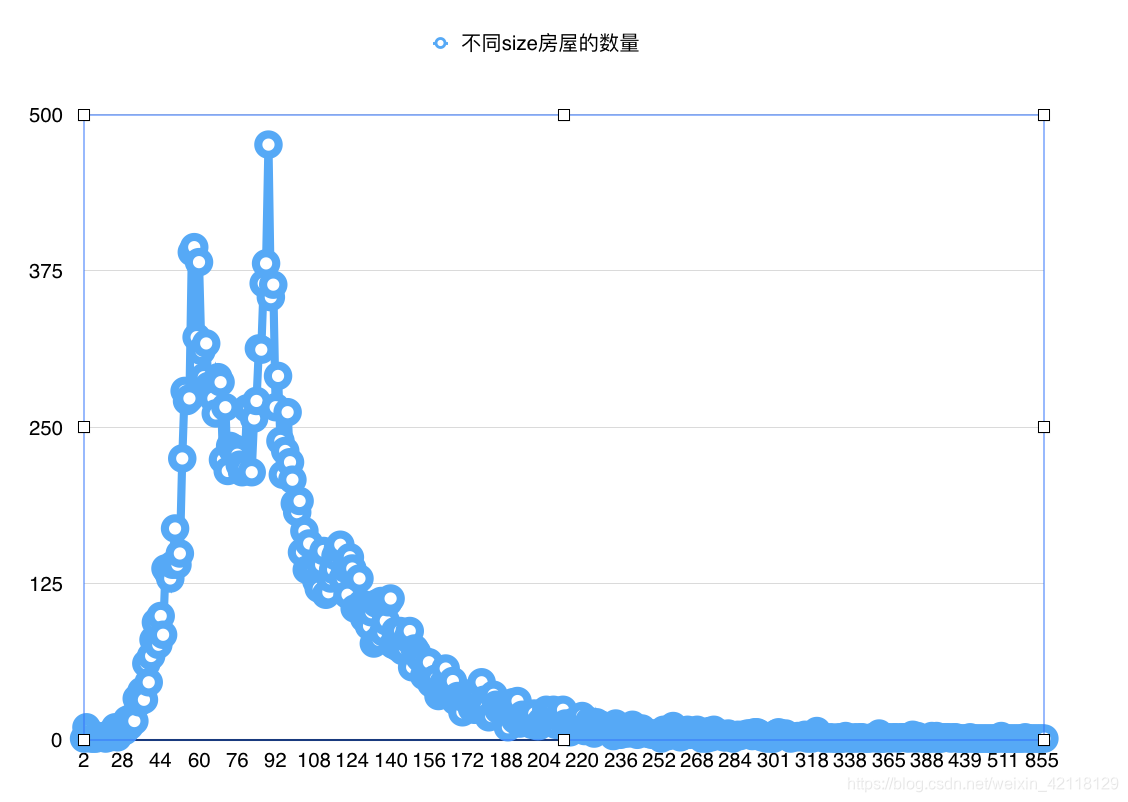
-
预处理:结合最开始的数据概览,知道了size的最大值为1019,以及对房屋面积大小概念的经验,可以先把size值大于500的先去掉,然后再进行归一化。
select cast(cast(size as int)/10 as int)*10 s, count(*) c from lj group by s having s < 400 order by s;
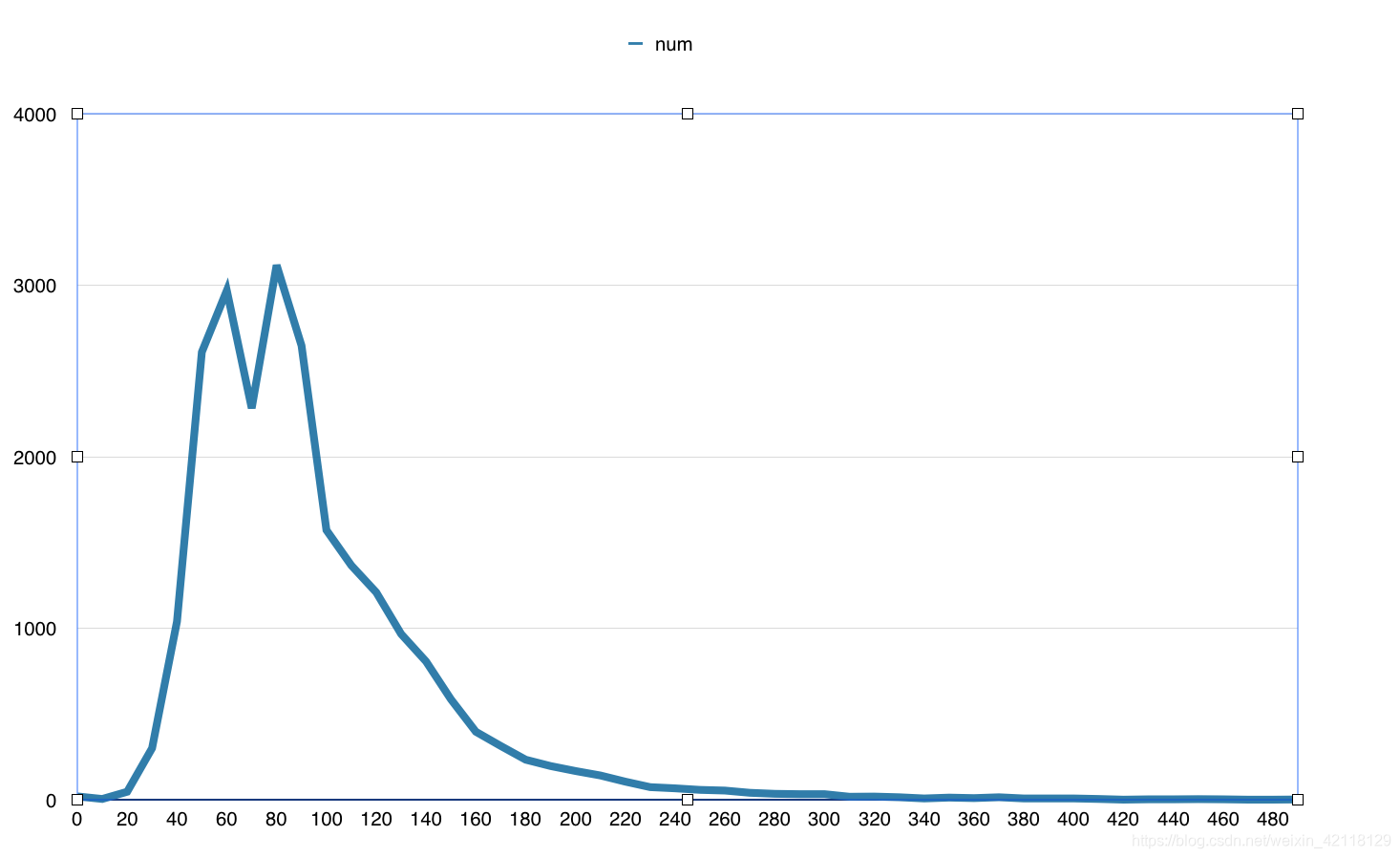
- 归一化后结果展示:
- 对比上图,归一化后的展示结果,房屋面积数量的走势更加清晰,size以20个单位为一组,变得更加紧密。
- 总结:根据上图分析,北京大多数二手房面积均小于160平方米,后面出现了长尾型分布,面积在200~500平方米可能是参与二手交易的别墅。
Size与Price分布
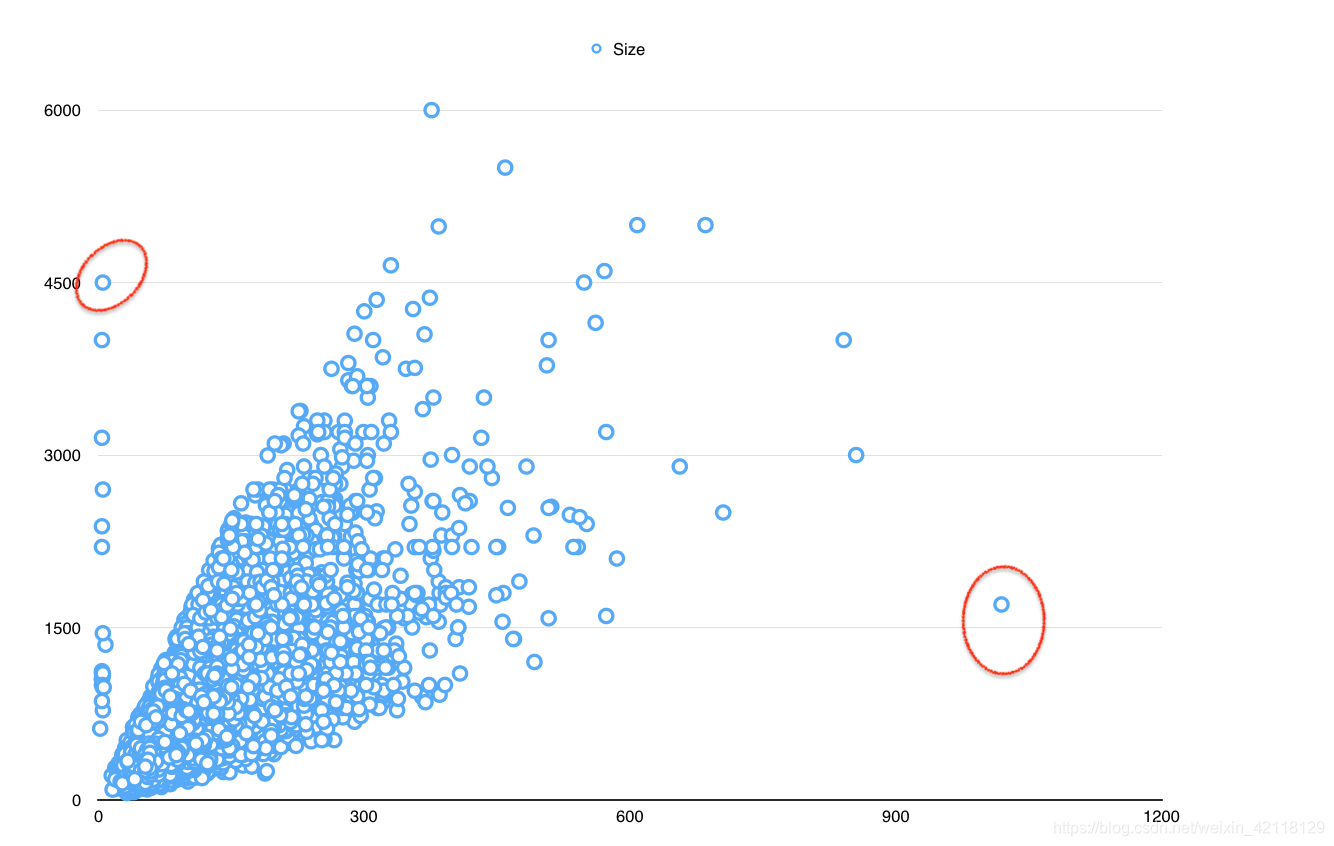
- 总结:观察Size与Price之间的散点图,发现Size特征基本与Price呈现线性关系,符合基本常识,面积越大,价格越高。但是有两组明显的异常点:1.面积不到是十平米,但是价格超出4000万。2.面积接近1000平方米,但是价格却很低。需要查看一下是什么情况。
#####情况一:Size < 10
select region, direction, district, elevator, floor, garden, id, layout, price, renovation, size, year from lj where cast(size as int) < 10;
得到以下数据:
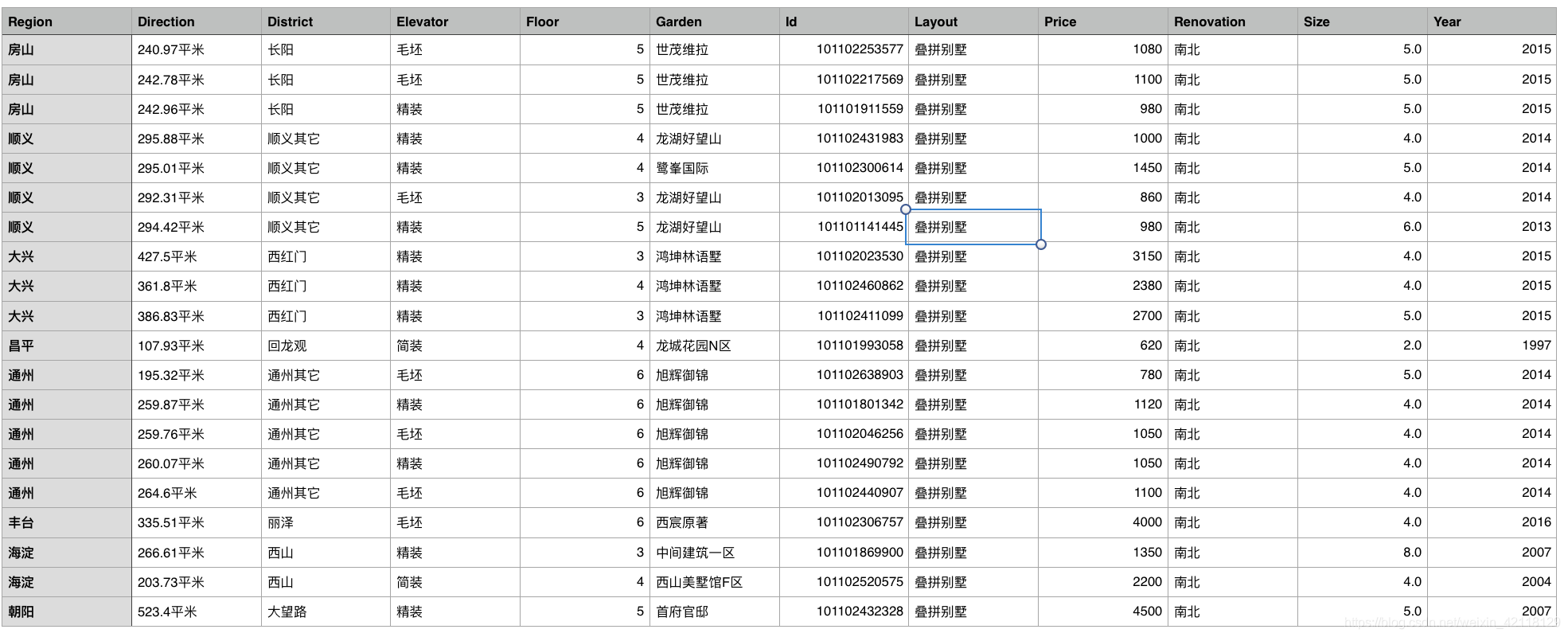
- 经过观察发现这组数据是别墅,房屋朝向,电梯,还有装修这三列数据都出现了错误,出现异常的原因是由于别墅结构比较特殊,字段定义和普通而二手房不太一样,导致爬取的数据错位。
#####情况二:size > 1000
select region, direction, district, elevator, floor, garden, id, layout, price, renovation, size, year from lj where cast(size as int) > 1000;


- 观察这个异常点不是普通的民用二手房,而是一个商用房,所以1房间0卫才有1019平方米这么大的面积,和我们的经验判断也是吻合。
- 修改:去掉以上的误差数据,对price进行一下平均值处理。
select cast(size as int) s, avg(price) from lj group by s order by s;
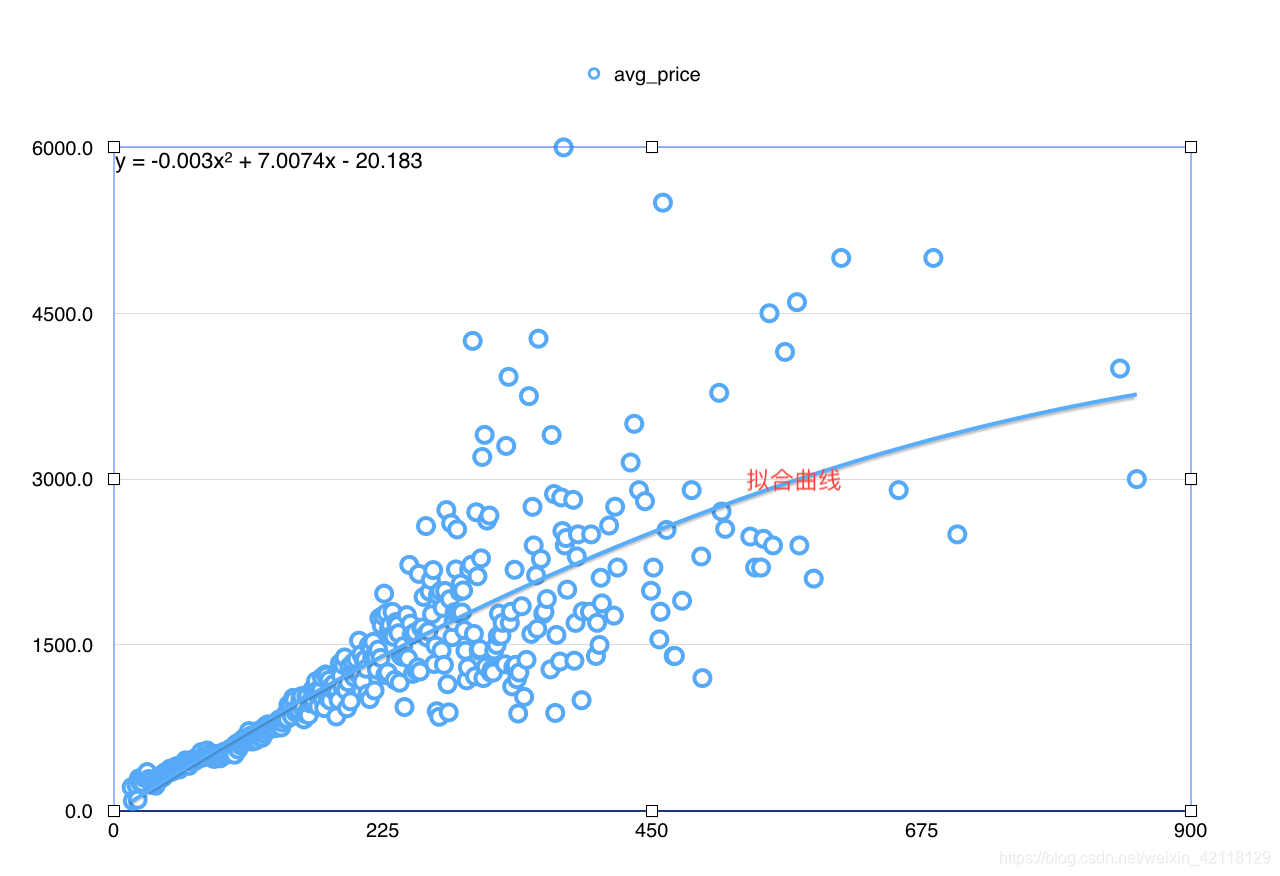
- 总结:利用numbers自带的趋势线拟合出来的曲线,基本接近于线性。虽然是numbers自带的拟合功能,但是这就是机器学习的线性回归啊。
Layout特征分析
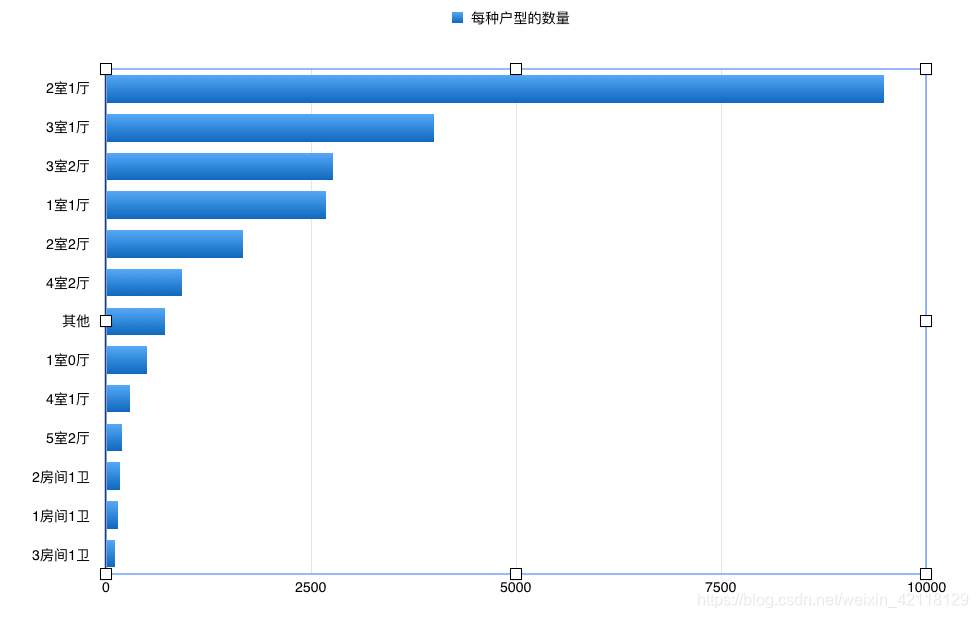
对于Layout特征分析,可以统计不同户型的房子的数量。
统计后的结果如图: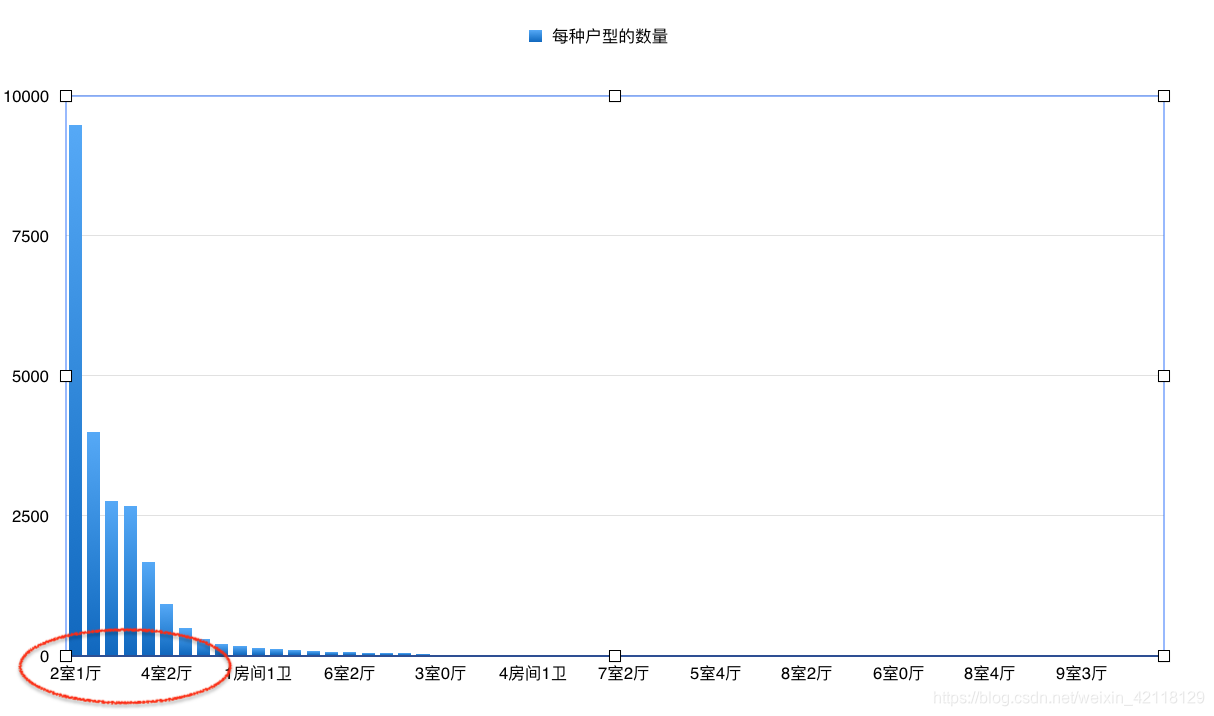
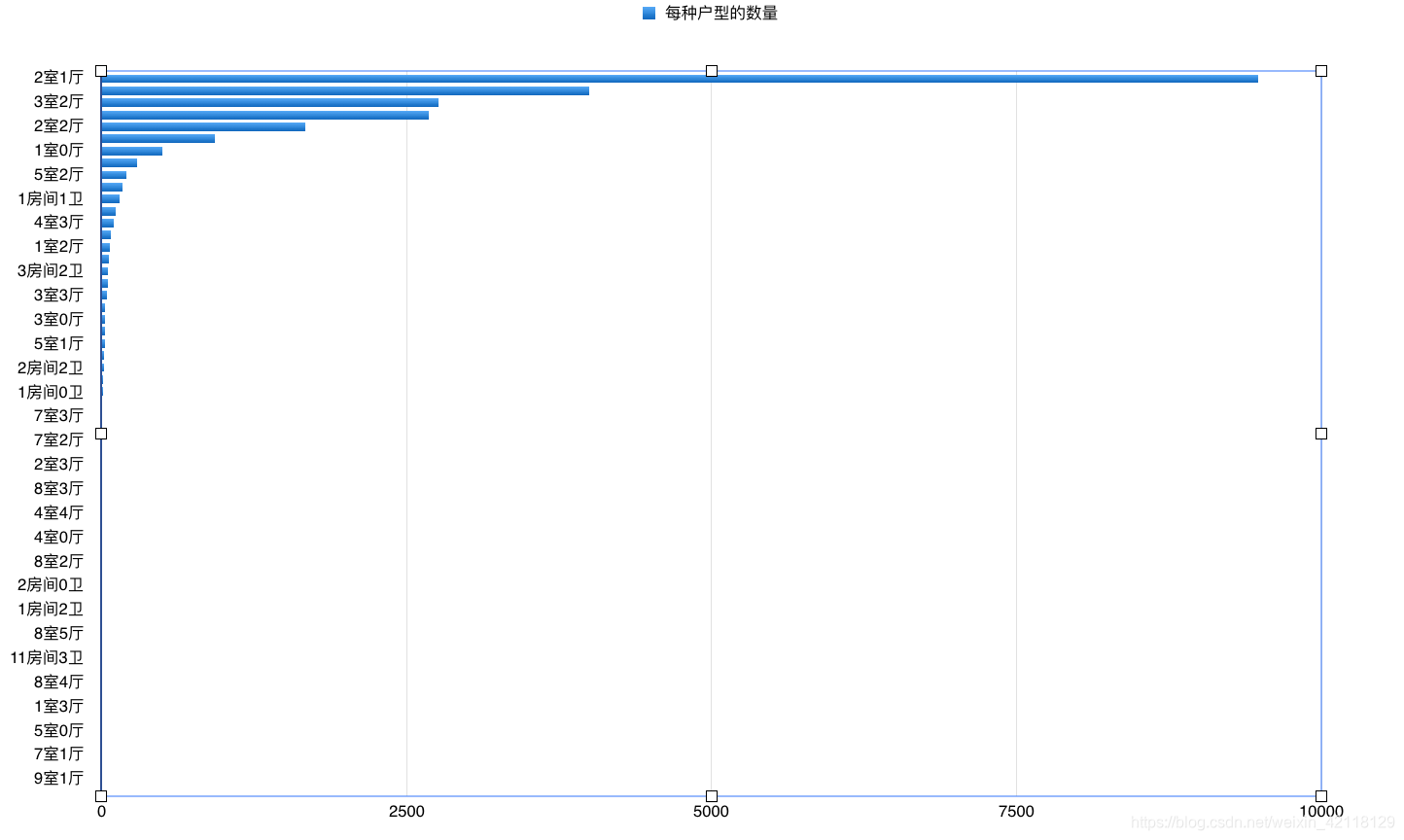
- 这次数据可视化,利用同一组数据,在numbers里画了两种统计图表展示统计的结果,可以观察出条形图给人的感觉更加地清晰,从上到小,不同户型之间的数量对比一目了然。而柱状图则不那么明朗,并且还有一个严重的缺点就是横坐标的文字的长度会影响整体的展示,如上图,甚至会生横坐标重叠的问题,而条形图很好的避开。
*综上,体会到数据可视化的方法应该是更加多元化的,要深刻理解并熟练掌握不同种类的统计图表的优劣,能够让别人更加直观的看出数据背后的规律。
- 总结:观察图表可以看出,各种厅室的组合搭配,还有9室3厅,4室0厅这样奇怪的结构,不过两室一厅还是占比最多。
- 改进:观察发现后面有大量的Layout特征数量非常少,只有1~2套左右,这样展示的图表过于密集不够直观,可以把它们求和单独算作其他。
Renovation特征分析
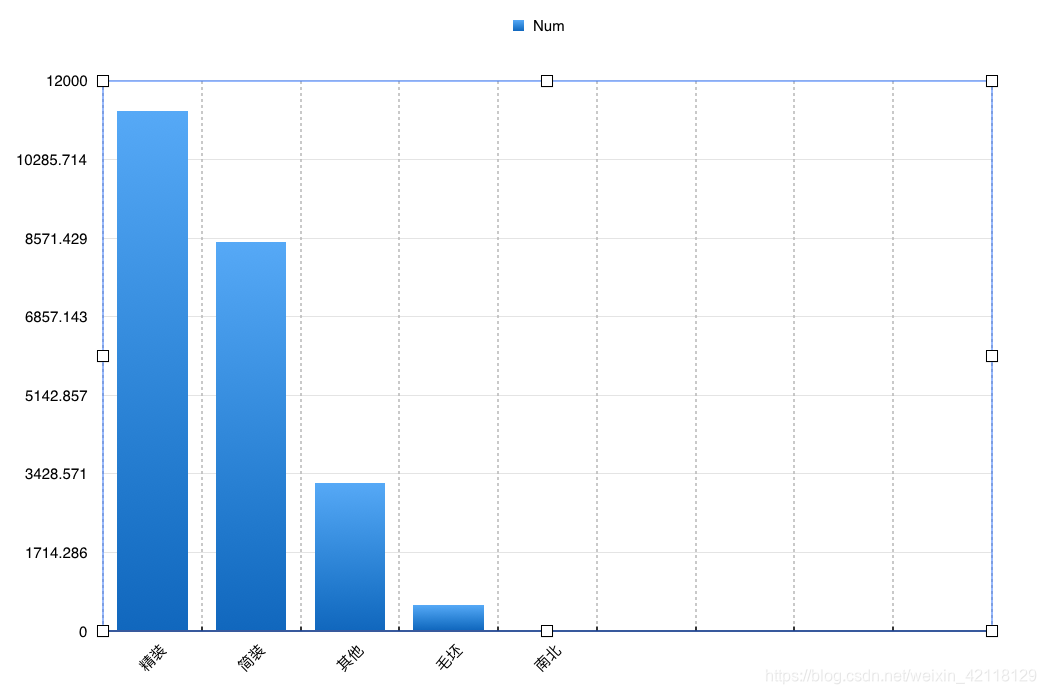
对于房屋装修特征,我们可以分析二手房装修特征的数量分布,以及与价格的关系。
Renovation特征数量分布
select renovation r, count(*) c from lj group by r order by c desc;
可视化结果:
-
发现Renovation装修特征中竟然有南北,它属于朝向特征,但是在柱状图上观察不到它的数量是多少,换饼状图看一下。
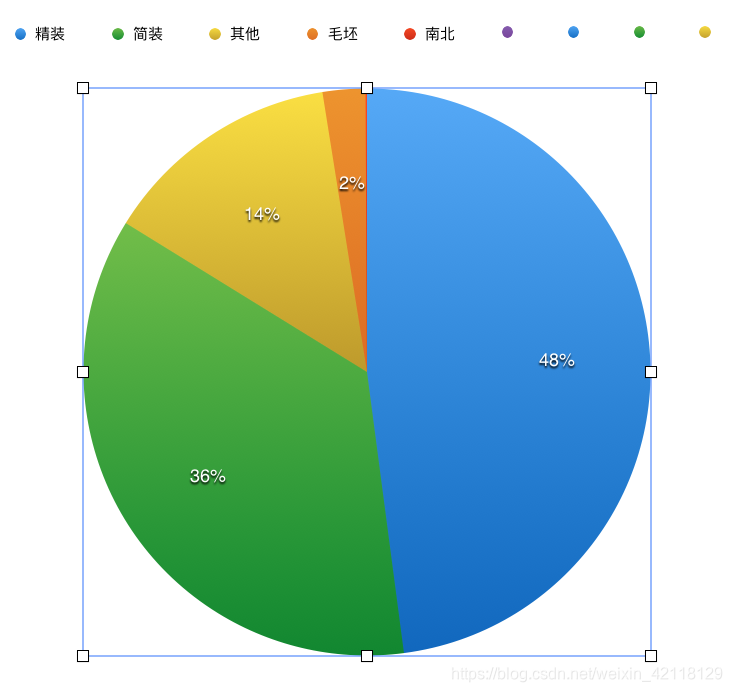
-
从饼状图中可以直观的看出,南北特征的数据占整体的2%。在统计学中,百分数比绝对数值和相对数值更能直观的表达出数值的大小和意义。
-
分析:南北朝向的特征,可能是爬虫过程中一些信息的位置为空,所以导致朝向的特征出现在这,所以要把这些数据去掉。
select renovation r, count(*) c from lj group by r having r != '南北' order by c desc;
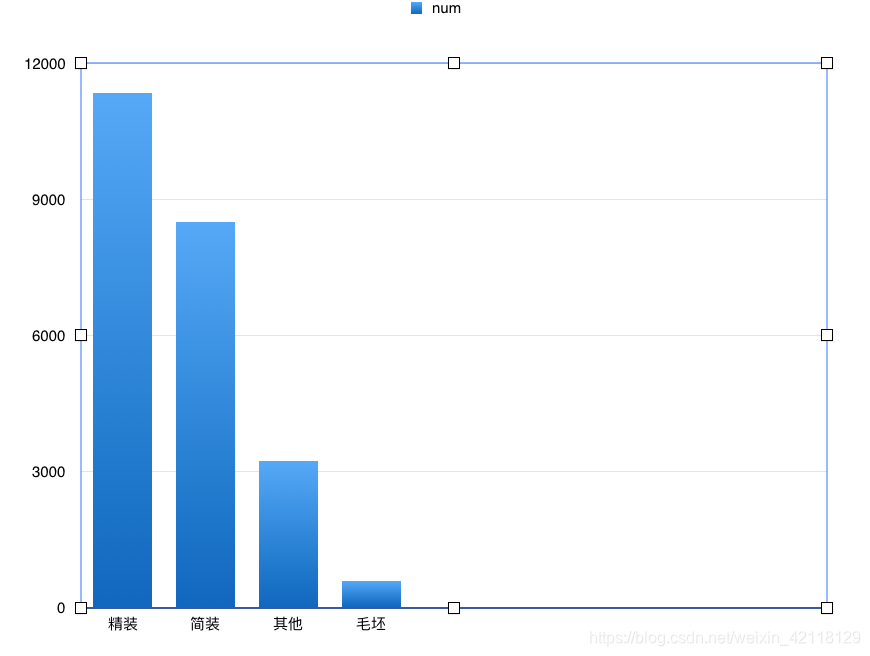
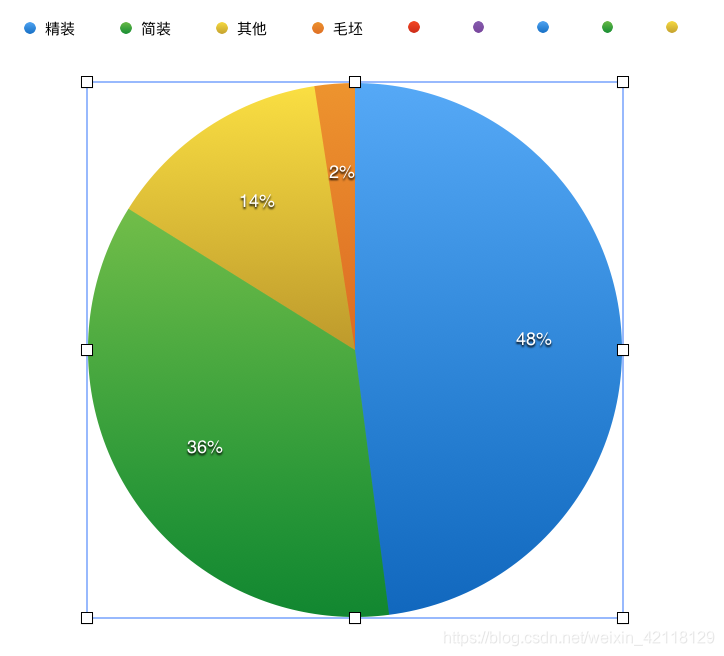
Renovation与price的关系
select renovation r, avg(price) p from lj group by r order by p desc;
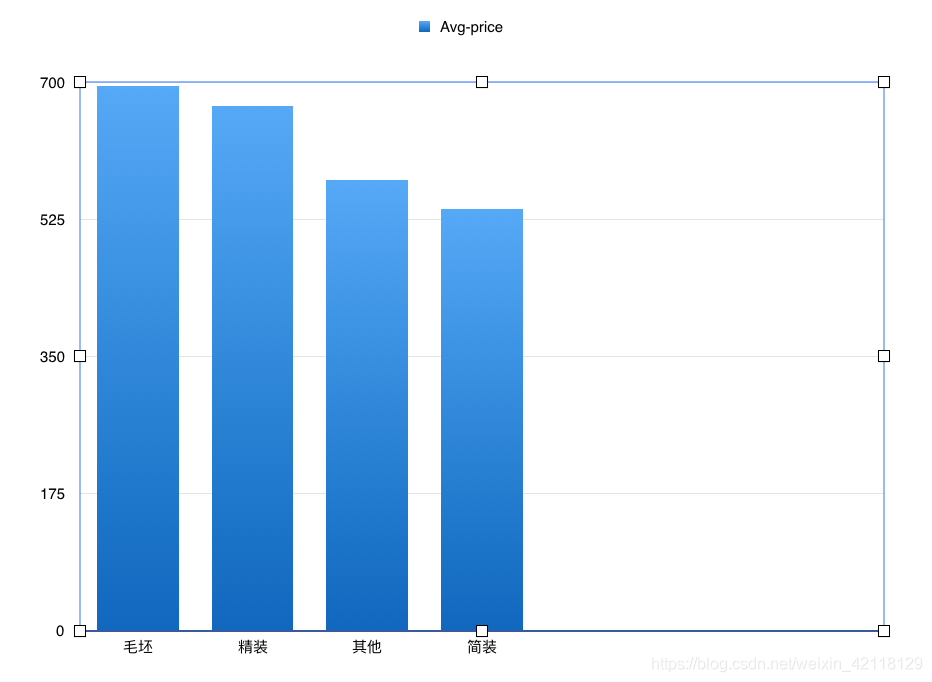
- 分析:从以上图表可以观察出,二手房中精装房的比例接近半数,在价格排行中,毛坯房的均价是最高的,精装房其次。
Elevator特征分析(重难点)
对于有无电梯特征,可以分析一下北京各个区域电梯数量的TGI。
在数据概览的时候,我们就发现Elevator特征有大量的缺失值。这对我的分析有很大的影响。
select elevator e,count(*) from lj group by e;
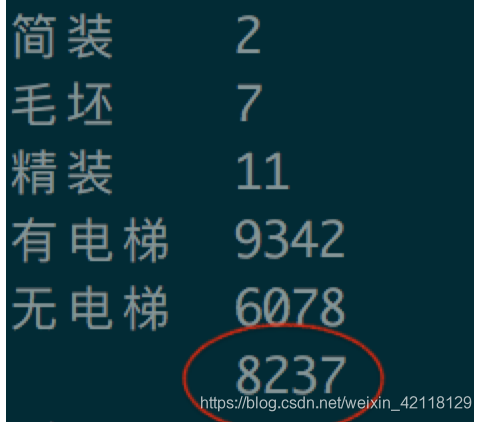
Elevator缺失值数量为:8237
这么多的缺失值怎么办呢?这个需要根据实际情况考虑,常用的方法有平均值,中位数填补法,直接移除,或者根据其他特征建模预测等。这里面我考虑填补法,但是有无电梯不是数值,不存在平均值和中位数,我想到一种填补的方法:
- 可以根据经验,根据Floor来判断有无电梯,一般楼层大于6都是有电梯,而小于等于6层一般都没有电梯。
- 改进:以上的填补法其实是基于我们的生活经验做出的一种假设,现实问题建立模型中总是缺少一些信息条件,这时候就要做出一些合理的假设,使条件完备,再继续分析。假设越接近于现实,引入的误差也就越小,考虑上面的方法,以6层为分割线,以下就是无电梯,以上就是有电梯好像有些太绝对了。我修改一下假设的填补条件,如果一个小区只要包含一个高于9层的房子,或包含一个有电梯的房子,那么这个小区有缺失值的房子就是有电梯的,反之则扔保留空缺值。
Floor特征分析
对于Floor特征,可以分析不同楼层的二手房数量分布,以及楼层与房价的关系。
Floor特征数量分布
select cast(floor as int) f,cast(count(*) as int) c from lj group by f order by f
可视化结果:
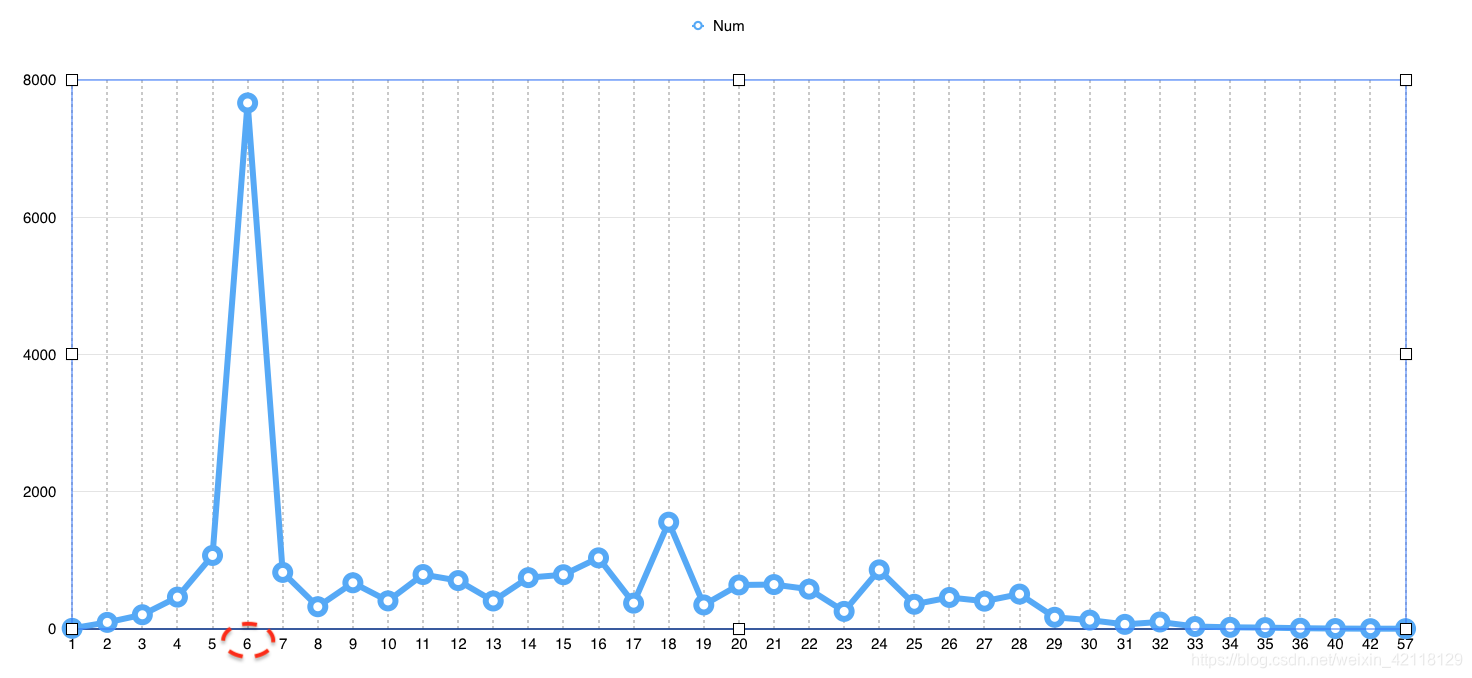
分析:从图表中可以观察到,6层二手房的数量最多,有一个数量增长上的飞跃。
- 改进:可以对楼层的数量求和,这样可以看到楼层数量的增长趋势。
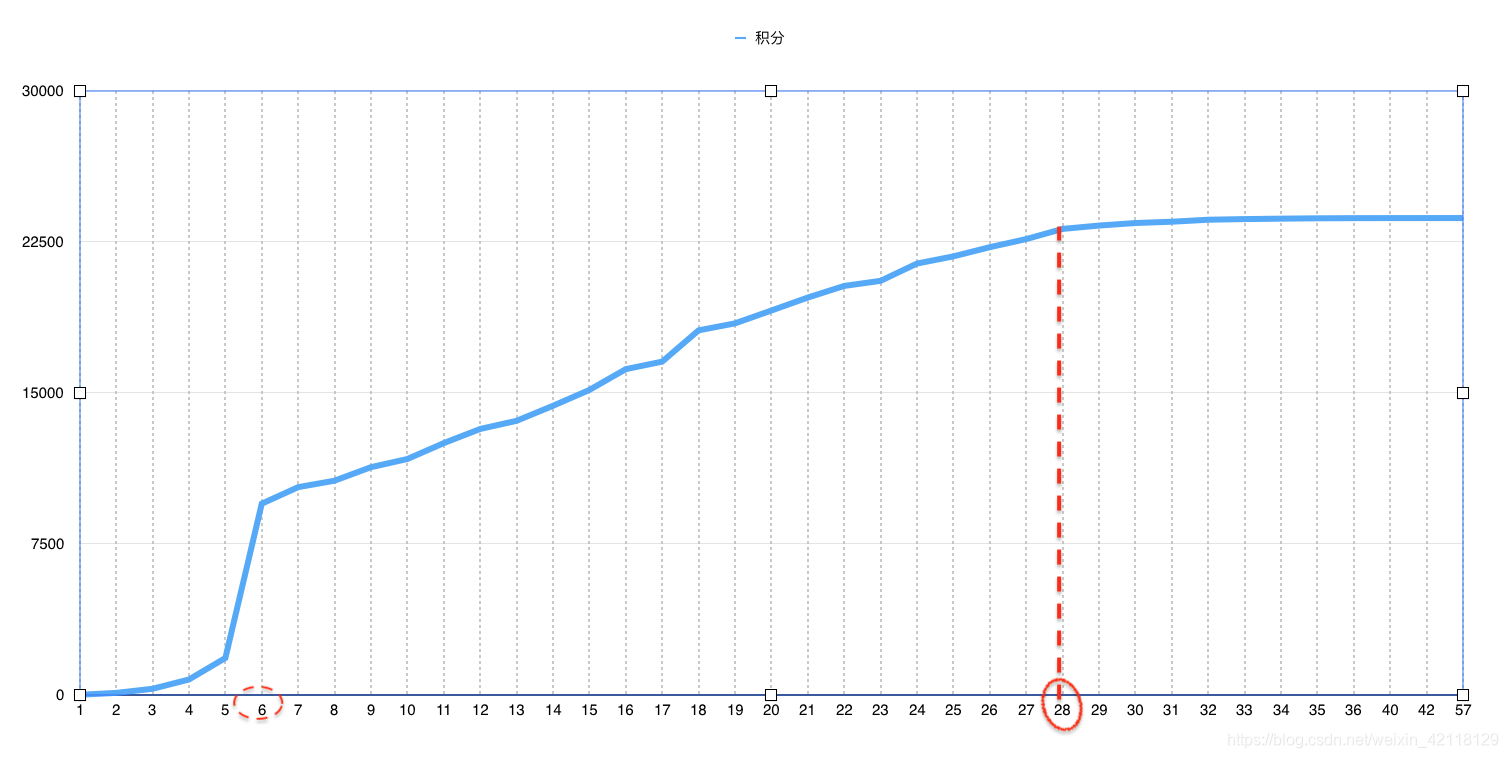
总结:从求和图表可以更加明显地看出从5层到6层有一个断崖式地增长,表明6层的二手房的数量最多,而且还能看出大多数的二手房都是28层以下的,29层~57层的数量非常少。
Year特征分析
房屋的建造年份与房屋的产权年限直接相关,也是二手房买卖中买家会比较看中的一点,对于Year特征可以从建造时间与房屋价格的关系,与size特征结合分析定义老破小房屋,分析全市与市里各区域老破小房屋的TGI比例关系来分析。
(注)Year与price的分布关系
北京市各区域老破小TGI比例分布
select cast(year as int) y, count(*) c from lj group by y order by y;
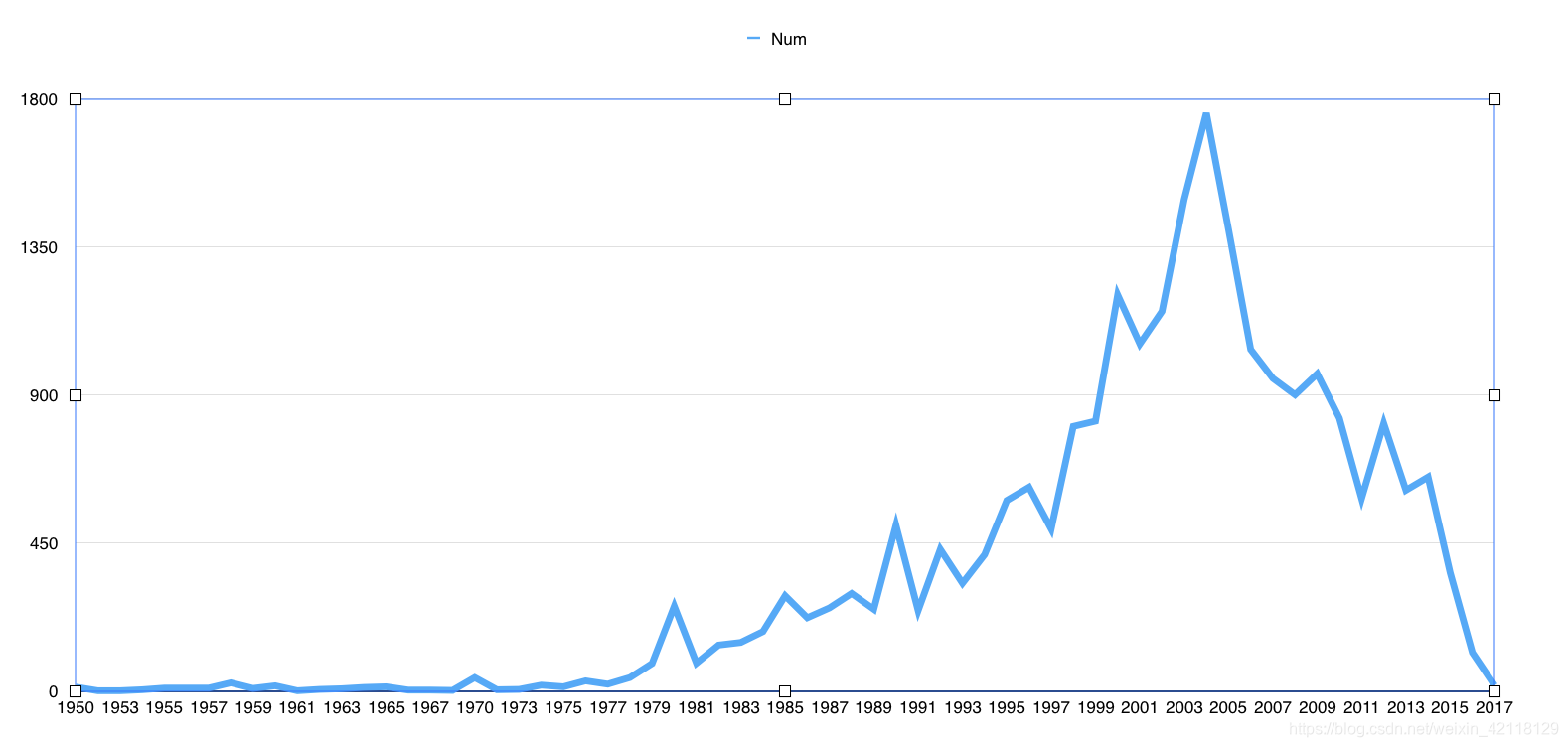
从上图中可以看出1990年前房屋建造的数量比较少,1990年到2005年一直持续走高,2006年有开始急剧下滑。
综合上图的分析以及之前房屋面积特征的分析,在分析之前要先对老破小下一个定义,做一个假设再进行下面的分析。这里定义size<40且year<1990,满足这两个条件的房屋就是老破小。
select size s, year y from lj where size < 40 and year < 1990;
- 全市老破小的TGI:58/23677 = 0.00244963
北京市各区域老破小TGI分布:
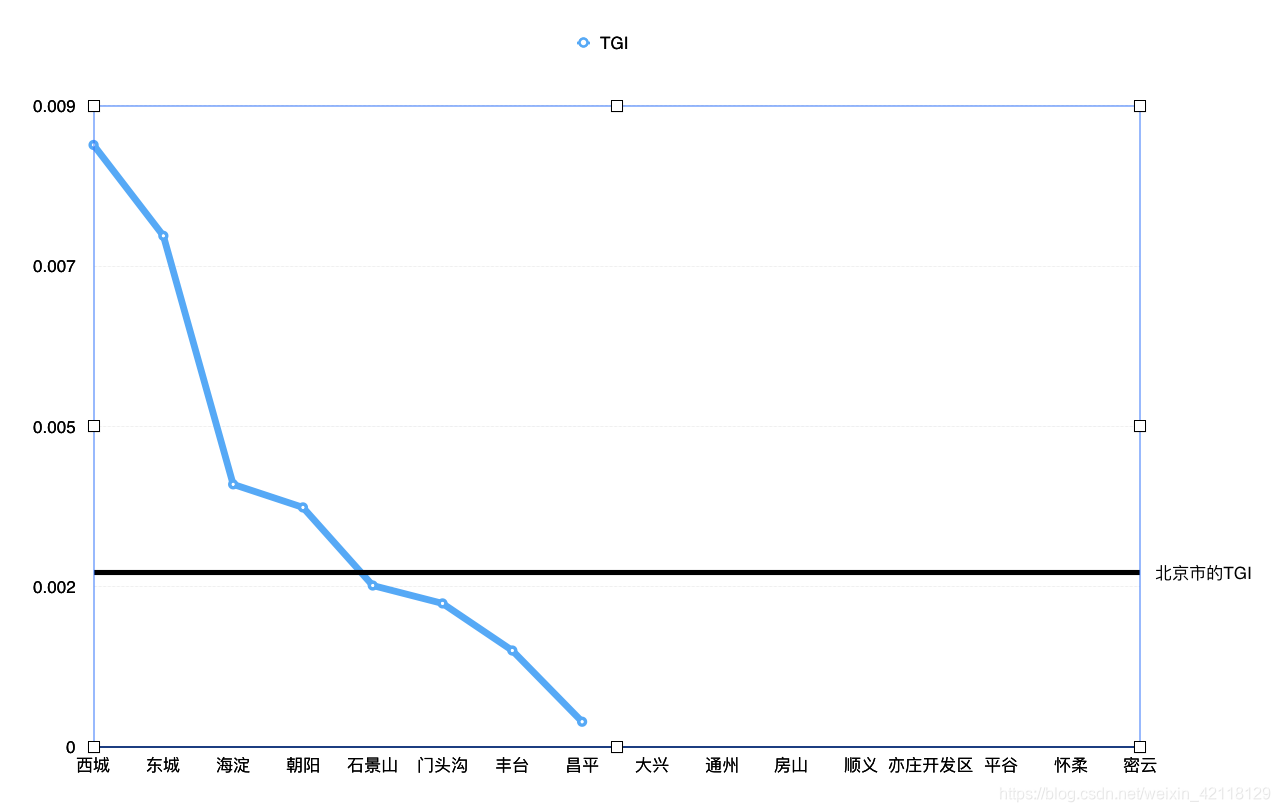
分析:西城,东城,海淀,朝阳四个大区的老破小TGI比全市的要高,说明这四个区域的二手房老破小的占比要高于北京市的平均水平,其中西城和东城的比率最高。其他的区域二手房老破小的占比要低于北京市的平均水平。
Direction特征
对于Direction特征,我们可以分析房屋朝向的数量分布,以及和价格的分布关系。
Direction的数量分布
select direction d, count(*) c from lj group by d order by c desc;

从上表中可以看出有很多脏数据,朝向名称混乱,还有平米数的错误数据,要把这些数据去掉。
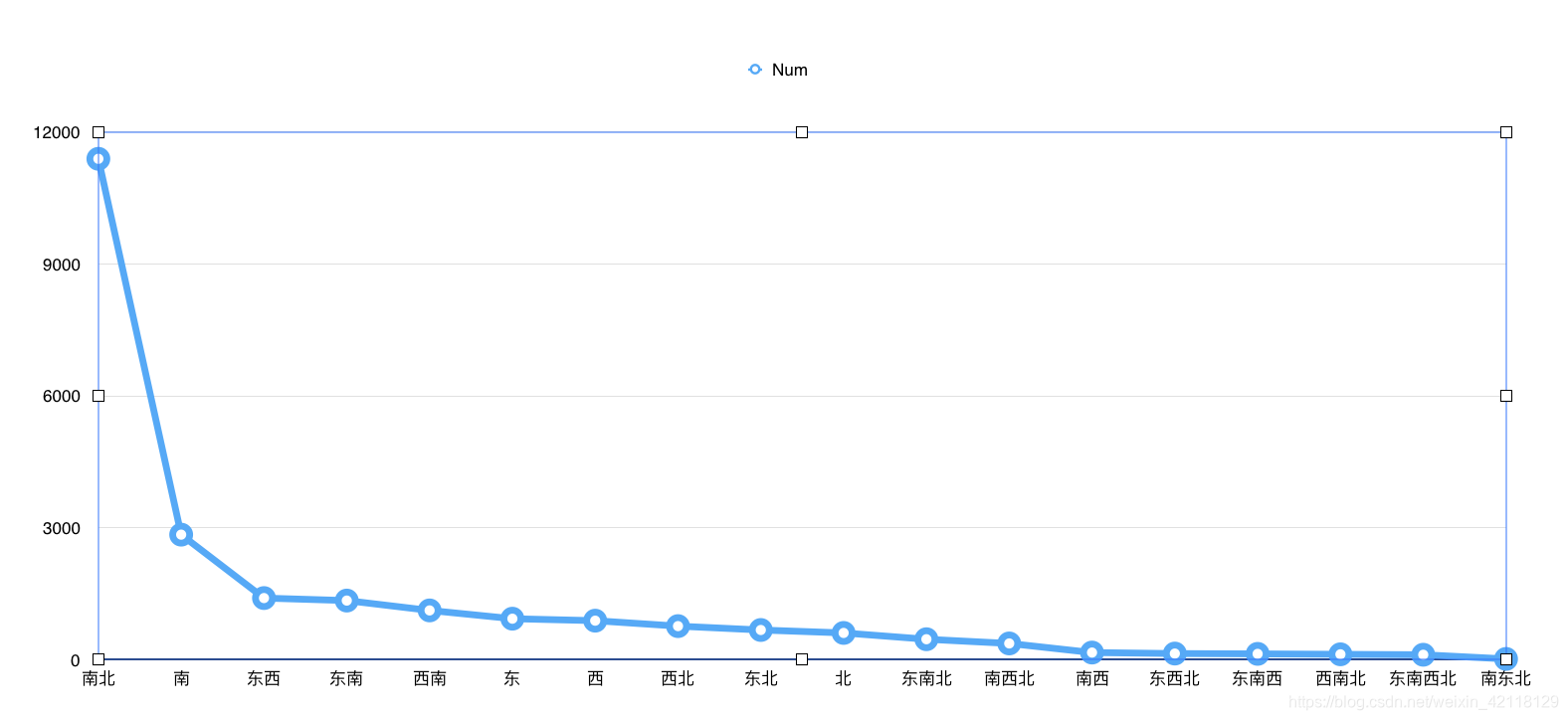
从上表可知南北朝向的二手房数量最多。
Direction的数量与价格分布
select direction d, count(*) c from lj group by d order by c desc;
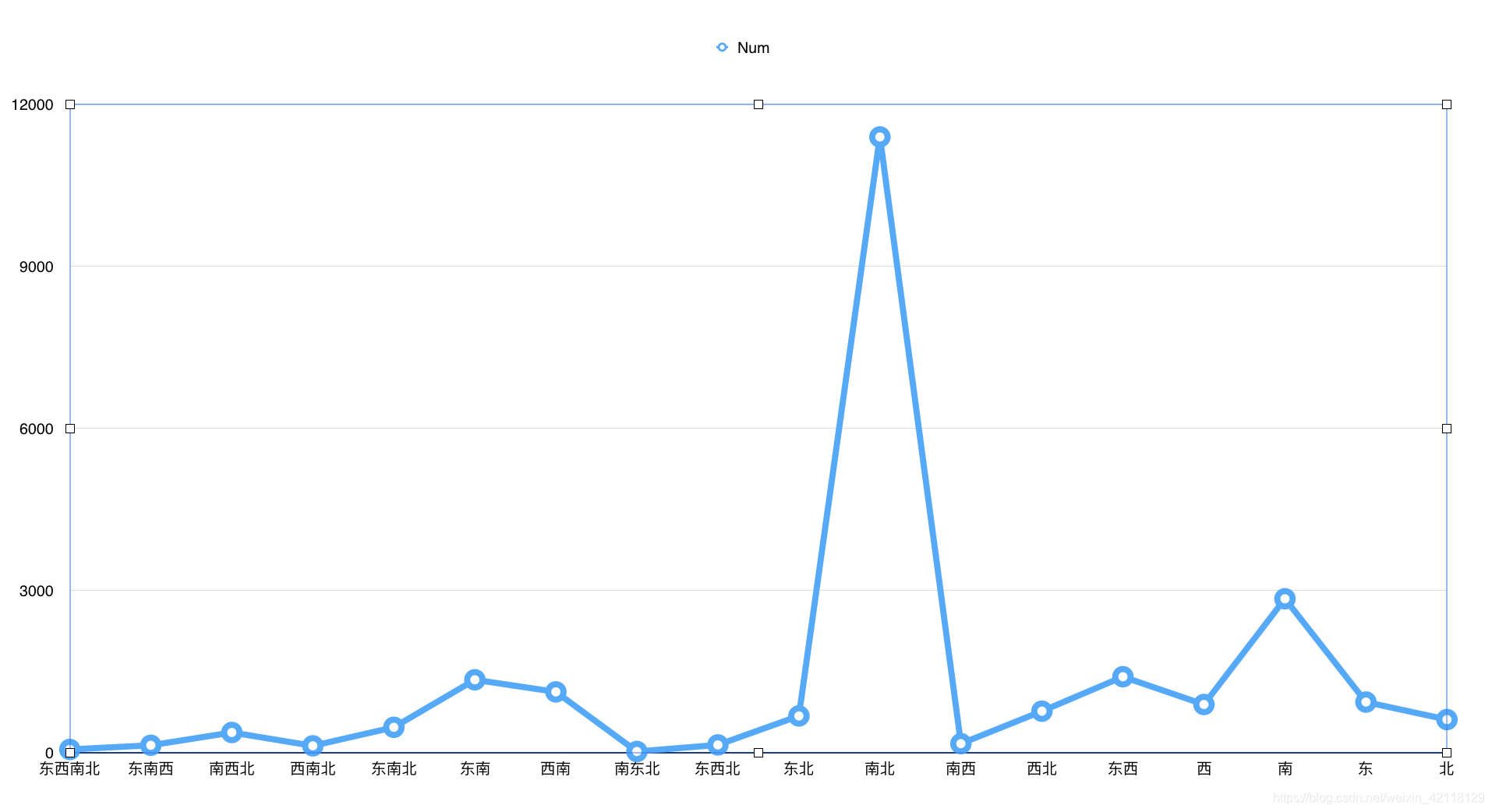
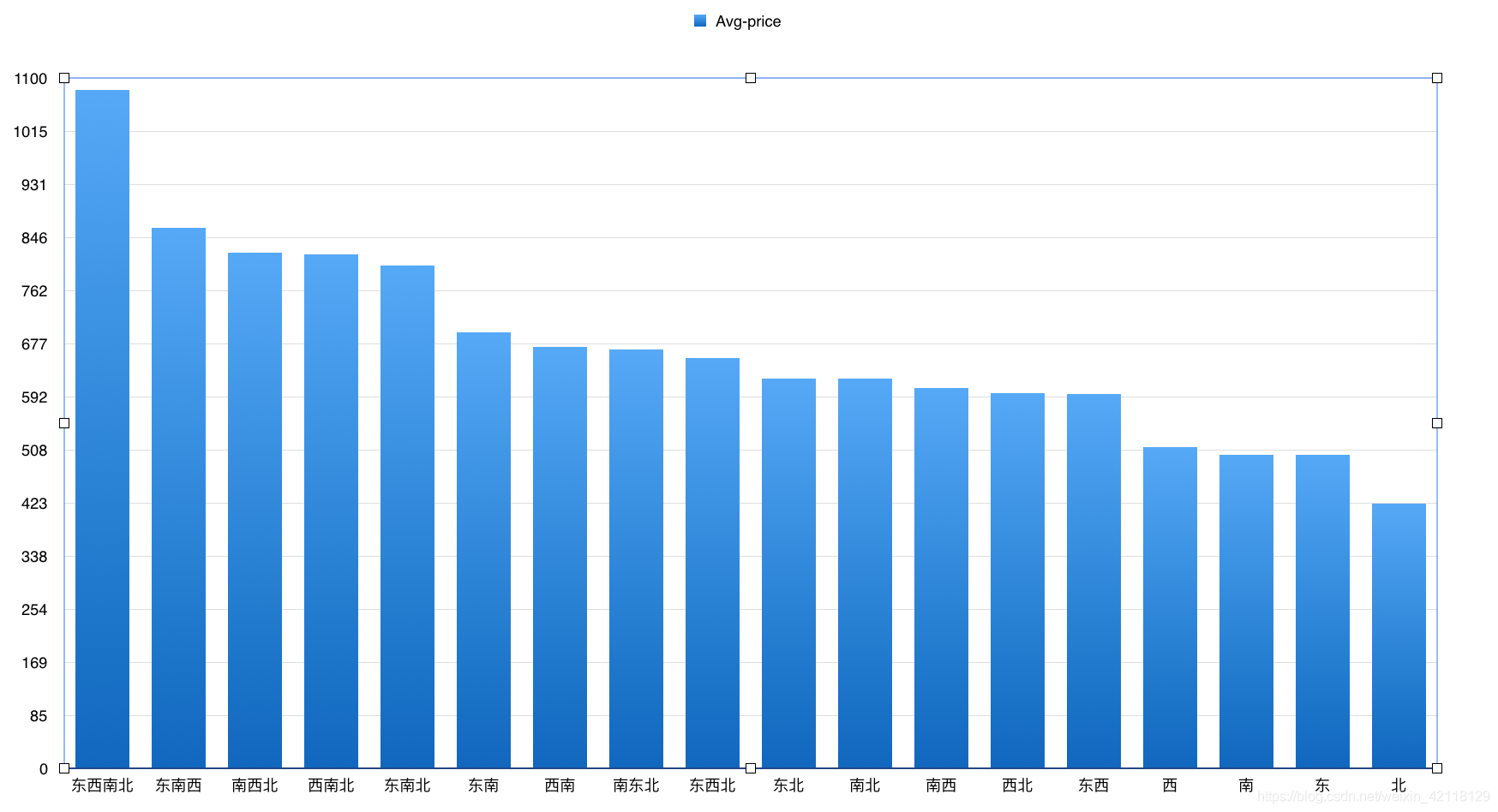
结合上面的图表数据画一个双y轴图:
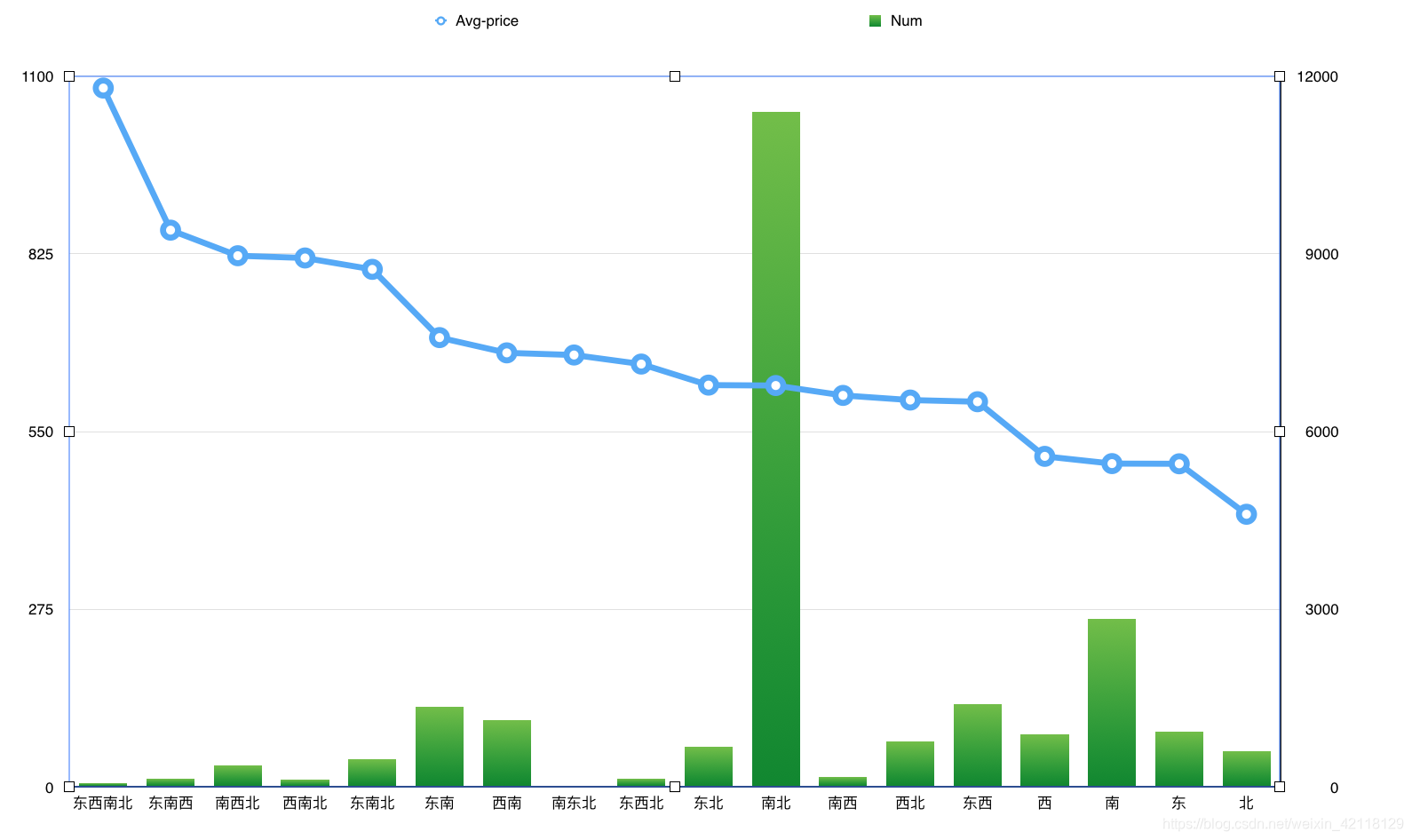
-
分析:双轴图可以在同一个维度上观察不同特征的分布情况并进行对比。由以上两图可以看出南北朝向的房屋数量是最多的,南北朝向的房屋,通透,采光好,符合买房者的需求,开发商在建造房屋时应该会尽量增加南北朝向的房屋。在价格分布上,东西南北朝向的价格最高,应该是别墅。东,西,南,北单朝向的房子价格均偏低,尤其是朝北的房子。
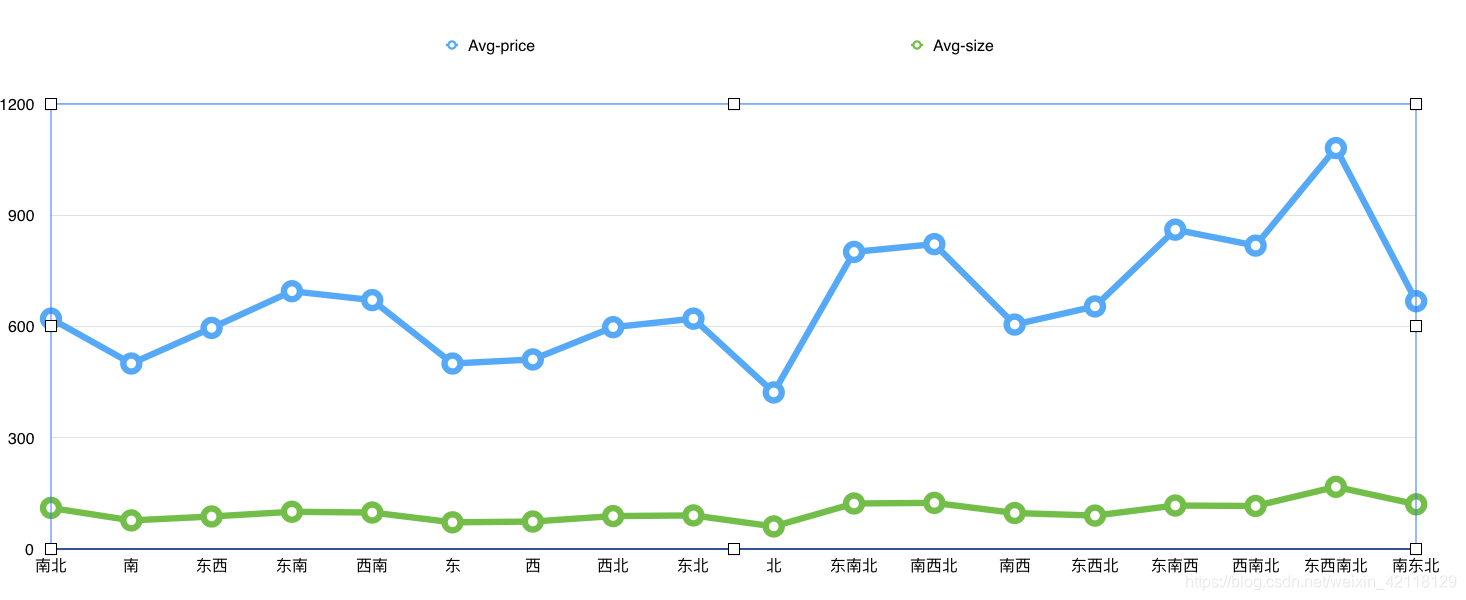
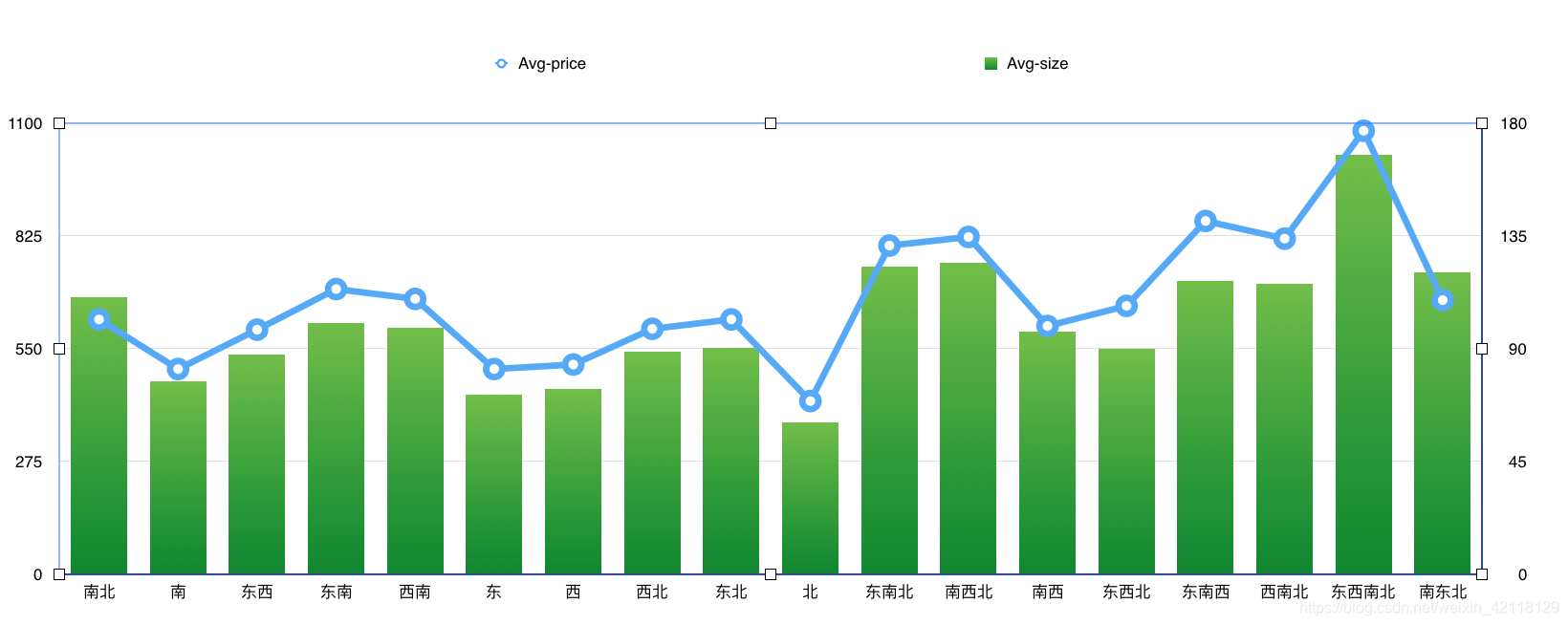
-
分析:观察上图,在朝向相同的情况下,房屋的平均价格和平均面试仍是处于正相关的,这与之前在画价格与面积的散点图得到的结论是一样的。
District特征
对于District特征,可以分析商业区和价格的分布,筛选出房屋均价的top10的district,查看全部特征值,分析价格高的原因。
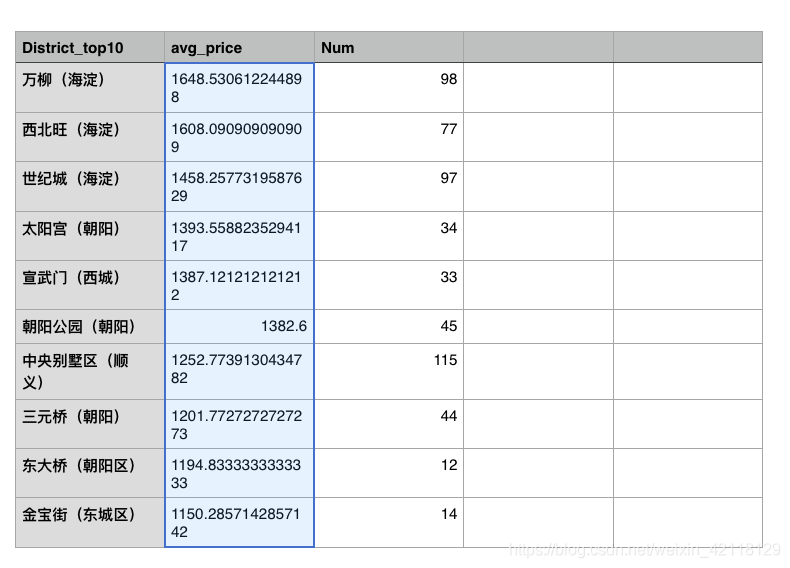
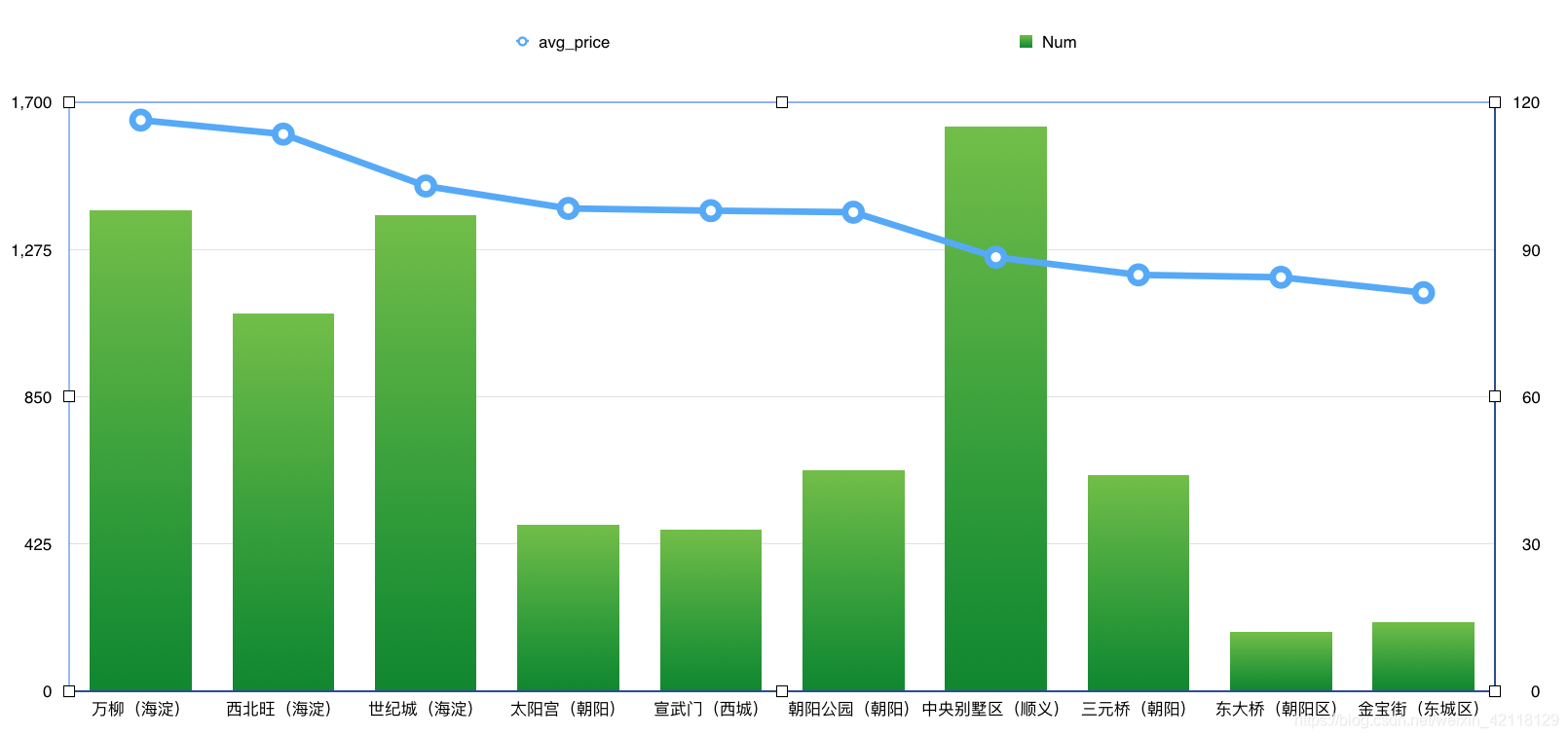
- 分析:从图表中可以看出,万柳的房子均价是最高的。
展开查看万柳二手房的其他信息:
select direction, district, elevator, floor, garden, layout, price, renovation, size, year from lj where district = '万柳';
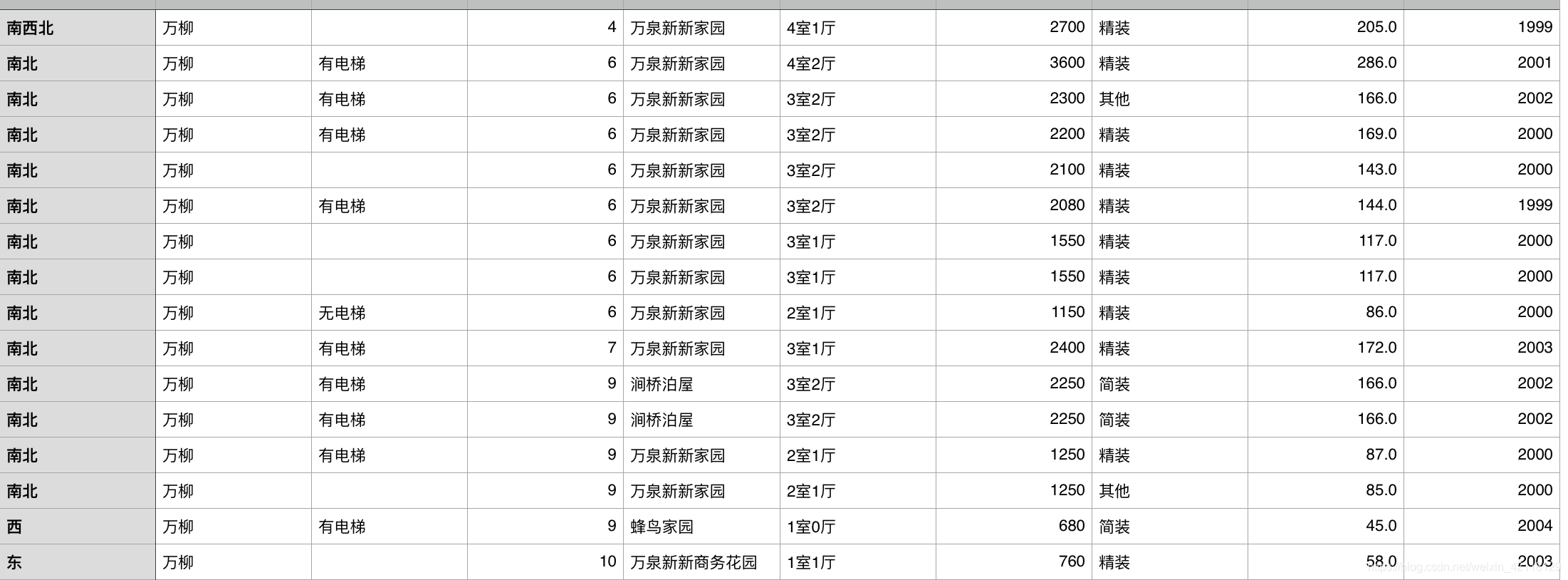
- 分析:表中的数据各个特征的的关系基本上符合之前分析的规律。除此之外在网上查阅了万柳的房价为什么这么高?
- 大致回答:万柳毗邻世纪金源购物中心,万柳高尔夫球场,中关村三小,非常优越。还有一些小区整体客户定位就是富人,房型较大,社区基础设施建设较好,地近三环,接近市中心等。
总结:从以上数据与图表的分析来看,现有的数据只能分析出影响二手房房价简单的具有线性关系的因素,对于准确的定位还欠缺一些重要的特征数据,比如是否是学区房,交通是否便利等。
项目总结:
Region特征:北京二手房均价和数量分布呈中心辐射状
Size特征:北京大多数二手房面积均小于160平方米,房屋面积与价格呈线性关系
Layout特征:2室1厅的房屋格局数量最多
Renovation特征:精装房数量最多,毛坯房价格最高
Floor特征:6层的房屋数量最多,大多数房屋均在28层以下
Year特征:西城区和东城区二手房老破小数量占比远超全市水平
Direction特征:南北朝向的二手房数量最多,价格和朝向的个数成正比
District特征:对于二手房房价的准确定位需要更多的特征数据
思考
综上,我利用sql对链家北京市二手房的交易数据进行了多角度的分析,更加熟练了sql的使用,以及数据可视化有了更新的认识,但是还有很多需要改进的地方:
- 更加熟练的使用python爬取数据
- 需要寻找更多更好的售房特征
- 需要做更多的特征工程工作
- 数据分析时能更多角度,全方位的查看数据,结合业务需求得到更有价值的信息
- 学习更多的统计学的知识,和数据可视化的知识。
转载自原文链接, 如需删除请联系管理员。
原文链接:链家北京二手房交易数据分析,转载请注明来源!