啥都不说,直入正题。
思路:分析请求地址——解决登陆问题——获取页面后筛选有用信息——优化相关算法
一、分析请求地址
通过分析教务处官网,发现请求URL为http://run.hbut.edu.cn/StuGrade/Index
并且得到了登陆时所需要post的表单数据。
二、登陆
通过requests模拟请求,其中验证码部分需要定向到生成验证码的url,发现url对应的是一个图片文件,因此我选择直接利用open在本地新建一个图片文件,利用write写入,人工输入验证码。
其中部分代码如下:
captcha = requests.get('http://run.hbut.edu.cn/Account/GetValidateCode', headers=headers) result = captcha.content fn = open('F:\hugongda.jpg','wb') fn.write(result) fn.close() def login(): data = { 'isRemember': '1', 'Password': 'XXXXXXXX', 'Role': 'Student', 'UserName': '1510821209', 'ValidateCode': input('请输入验证码:') } response = requests.post('http://run.hbut.edu.cn/Account/LogOn', data=data, headers=headers)
三、筛选有用信息
在对response对象进行分析之后,发现页面源代码很难使用正则表达式(其实是自身能力不足的缘故...)筛选出所需字符串,因此这里我们采用了BeautifulSoup模块:
grade = requests.get('http://run.hbut.edu.cn/StuGrade/Index',headers=headersgrade) soup = BeautifulSoup(grade.text,"html.parser") print(soup.h2.string) for i in soup.find_all("td"): print(i.get_text().replace(' ','').replace('不允许报名','').replace('已公布','').replace('已评教','').replace('\n',''))
强行使用replace,毕竟新手不知道怎么做,但是目的达到了。
四、优化算法
对data{}中的类似于Student和Password进行了处理,使每个学生都可以输入自己的学号和密码进行登陆。
但是还有一个问题,每个人在登陆的时候都必须自己在相应文件夹创建对应的用来存放验证码的hugongda.jpg文件,很麻烦,不知道怎么解决。
晒一下运行结果:

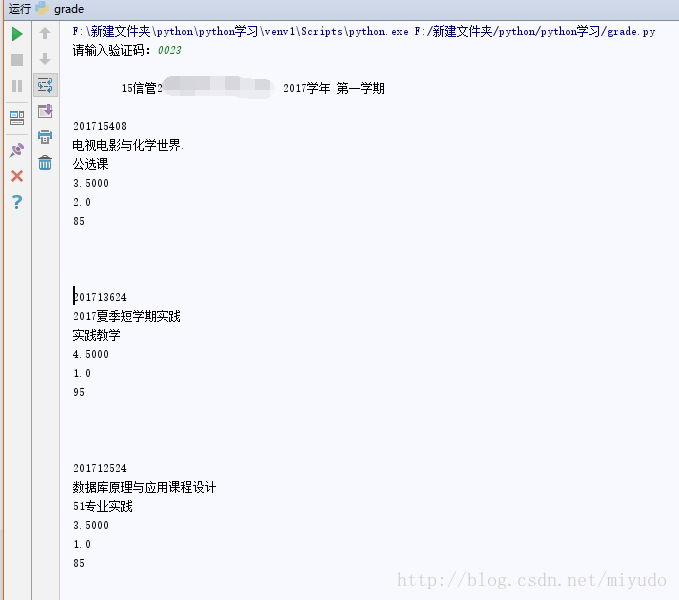
有待完善。
转载自原文链接, 如需删除请联系管理员。
原文链接:第一个爬虫(爬一下湖北工业大学教务处成绩),转载请注明来源!